🎹 InnoDB事务
2022年6月9日
- db
🎹 InnoDB事务
事务 [
Transaction]:一系列操作,要么全部成功,要么全部失败,不允许出现中间状态
1. 四大特性
1) 原子性[Atomicity]
- 事务的最小工作单元,一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节,
- 若事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样
- InnoDB 通过
undo log&redo log保证
2) 一致性[Consistency]
- 事务开始和结束后,数据库的完整性不会因为事务的执行而受到破坏
- 是目的,原子性 + 隔离性 + 持久性 共同作用保证了一致性
- InnoDB 通过 undo log 保证
3) 隔离性[Isolation]
- 数据库允许多个并发事务同时对其数据进行读写和修改的能力
- 不同事务之间互不影响,MySQL 提供
四种隔离级别 - InnoDB 通过
MVCC&锁保证
4) 持久性[Durability]
- 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失
- InnoDB 通过
redo log保证
2. 并发下容易产生的问题
1) 脏读 [dirty read]
- 场景:
- 事务A 读到了 事务B 修改过的但没有提交 的数据,此时若 事务B 发生了回滚,那么 事务A 之前读到的数据就是过期的脏数据
2) 不可重复读 [non-repeatable read]
- 场景:
- 在一个事务中,发生多次读取同一数据的情况,每次读取同一数据时出现数据不一致的情况
- 侧重于
update操作
3) 幻读 [phantom read]
- 场景:
- 在一个事务中,发生多次读取符合某种查询条件的记录数据,前后读取出现记录数据数量不一致的情况
- 侧重于
insert|delete
3. 隔离级别
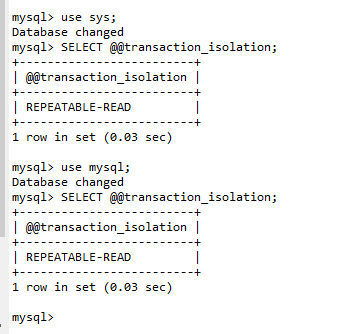
查看事务的隔离级别命令: [MySQL 8.0.26]
SELECT @@transaction_isolation
修改事务的隔离级别命令:
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level;
1) 读未提交 [Read Uncommitted]
- 一个事务还没提交时,它做的变更就能被其他事务看到
2) 读提交 [Read Committed]
- 一个事务只有被提交了,它的变更才能被其他事务看到
- 可通过
MVCC保证 - 只会对索引增加
Record Lock,不会添加Gap Lock和Next-Key Lock,并发度要比 RR 高很多 - 只支持
row格式的binlog,若指定了mixed作为 binlog 格式,在RC下,服务器会自动使用基于row格式的日志记录
3) 可重复读 [Repeatable Read]
- 一个事务执行过程中,不论什么时刻读到的统一数据都是一致的
- 可通过
MVCC保证,无需加锁影响性能 - InnoDB 默认隔离级别
- 通过
next-key lock锁住记录之间的“间隙” & 记录本身,防止其他事务在这个记录之间插入新的记录,可以避免幻读,但锁的粒度变大,死锁的概率也随之增大 - 同时支持
statement、row以及mixed三种
4) 串行化 [Serializable]
- 多个事务对同一记录进行读写操作时,若发生读写冲突,则相关事务会串行执行,必须前面的事务执行完成,当前事务才能执行
- 性能最差,却最安全
- 通过加锁保证
不同隔离级别下可能出现的并发问题:
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| RU | 🐠 | 🐠 | 🐠 |
| RC | 🐋 | 🐋 | |
| RR | 🐙 | ||
| Serial |
4. MVCC
1) 底层原理
聚簇索引中 2 个隐藏列
- 事务 id [
trx_id]6字节,每次递增 1- 当一个事务对某条聚族索引记录进行改动时,就会把该事务的事务 id 记录在
trx_id隐藏列里
- 回滚指针 [
roll_pointer]7字节- 每次对某条聚族索引记录进行改动时,都会把旧版本的记录写入到
undo log中 roll_pointer指向这个旧版本记录
Read View 4 个字段
creator_trx_id- 创建该 Read View 的事务的事务 id
m_ids- 创建 Read View 时当前数据库中活跃且未提交的事务 id 列表
min_trx_idm_ids中最小事务 id 的事务 id
max_trx_id- 创建 Read View 时当前数据库中应该给下一个事务分配的事务 id
2) 针对 RC & RR 的不同实现
RC 的实现
- 在事务执行过程中,每次查询操作都会生成一个新的
Read View,只能解决脏读,会出现 不可重复读 - 在事务期间读取数据的时候,在找到数据后,先会将该记录的
trx_id和该事务的 Read View 里的字段做个比较:- 若
trx_id<=creator_trx_id&&trx_idnot inm_ids- 说明这条记录的事务早就在该事务前提交过了,或是本事务自己修改的,该记录对该事务可见
- 若
trx_id>creator_trx_id&&trx_idnot inm_ids- 说明该事务读到的是和自己同时启动的另外一个事务修改的数据,但该事务不在
m_ids列表里,说明已提交,则该记录对该事务可见
- 说明该事务读到的是和自己同时启动的另外一个事务修改的数据,但该事务不在
- 若
trx_id>creator_trx_id&&trx_idinm_ids- 说明该事务读到的是和自己同时启动的另外一个事务修改的数据,但该事务还在
m_ids列表里,说明还未提交,因此沿着undo log链条往下找旧版本的记录,直到满足上面 2 条情况
- 说明该事务读到的是和自己同时启动的另外一个事务修改的数据,但该事务还在
- 若
RR 的实现
- 启动事务时生成一个
Read View,然后整个事务期间用同一个初始创建的 Read View - 在事务期间读取数据的时候,在找到数据后,先会将该记录的
trx_id和该事务的 Read View 里的字段做个比较:trx_id<=creator_trx_id&&trx_idnot inm_ids- 说明这条记录的事务早就在该事务前提交过了,或是本事务自己修改的,该记录对该事务可见
- 若
trx_id>creator_trx_id- 说明该事务读到的是和自己同时启动的另外一个事务修改的数据,此时不读取该条记录,而是沿着
undo log链条往下找旧版本的记录,直到找到trx_id<= 该事务 id 的第一条记录
- 说明该事务读到的是和自己同时启动的另外一个事务修改的数据,此时不读取该条记录,而是沿着
3) 优点
MVCC使得数据库普通读不会对数据加锁,普通的 SELECT 请求不会加锁,提高了数据库的并发处理能力- 普通读:
select * from chap where id = 22
- 当前读 [会加锁]:
select * from chap where id = 22 lock in share modeselect * from chap where id = 22 for update
5. 三大日志
WAL: 所有的修改都先被写入到日志中,然后再写磁盘
1) binlog
- 是什么?
- 记录数据库 表结构 & 表数据 的变更,例如 create | truncate | delete | alter | update | insert,不会记录 select
- 是什么样式?
- 逻辑日志
statement- 存储 sql 语句 + 事务 id + 执行时间
- 可能造成数据主从的不一致,例如使用了
now()uuid()函数等 - RR 隔离级别下支持
row- 将 sql 语句做的修改转换成具体数值 + 事务 id + 执行时间
- 内容更长,体积更大,同步 + 恢复时 IO 消耗更大,需要借助 binlog 工具解析,但是结果准确
mixed混合模式,MySQL会判断这条 SQL 语句是否可能引起数据不一致,如果是,就用 row 格式,否则就用 statement 格式
RR 隔离级别支持,RC 只能全部都是 row 格式

- 存在于哪些存储引擎中?
- MySQL 所有存储引擎均支持
- 什么情况下会用到?
- 数据恢复 & 主从复制等数据同步操作
- 什么时候进行写入?
- 事务提交时进行记录,写入成功说明该事务已经进入
commit状态
- 刷盘时机?
- 参数:
sync_binlog - 不同值下的策略:
0 : 写入文件系统,异步刷盘
1 : 同步刷盘,提交事务就会刷盘
N [N > 1] : 累积 N 个事务后刷盘

- 文件大小?
参数:
max_binlog_size可指定大小大小达到上限,会生成一个新文件继续写入

- 借助的内存空间?
binlog cache:每个线程独有查看单个线程 binlog cache 的大小指令:
binlog_cache_size,超过则会暂存磁盘
- 过期清理?
参数:
binlog_expire_logs_seconds
2) redo log
- 是什么?
- 记录在某个页上做了什么修改
- 是什么样式?
- 物理日志,xxxx 页做了 xxx 修改
- 表空间号 + 数据页号 + 偏移量 + 修改数据长度 + 具体修改的数据
- 存在于哪些存储引擎中?
- MySQL InnoDB 独有
- 什么情况下会用到?
- 数据库的崩溃恢复
- 当我们修改数据时,对内存数据进行了修改,但数据还未真正写到磁盘,此时若数据库挂了,就可以通过 redo log 对数据进行恢复
- 什么时候进行写入?
prepare: 事务开始时,redo log 记录变更信息,执行过程中也不断记录,表明事务进入prepare状态commit: binlog 写入成功,事务进入 commit 状态, prepare ==> commit
- 刷盘时机?
- 参数
innodb_flush_log_at_trx_commit - 不同值下的策略:
0:异步刷盘,后台每隔 1秒 刷盘,数据库挂掉则最多有 1秒 的数据丢失1:每次事务提交都进行刷盘 [default],只要事务提交成功则不会有任何数据丢失2:写入文件系统缓存,异步每隔 1秒 刷盘,数据库挂掉不会有任何数据丢失 & 文件系统挂掉最多有 1秒 的数据丢失
- 特殊情况:
当 redo log buffer 占用空间 > innodb_log_buffer_size 总空间一半时,后台线程也会主动刷盘

- 文件大小?
- 固定 ==
4G,环形数组形式 - 2 个重要属性:
write poscheckpoint: 如果write pos追上checkpoint,表示日志文件组满了,这时候不能再写入新的redo log,此时会出现 MySQL 偶尔变慢的情况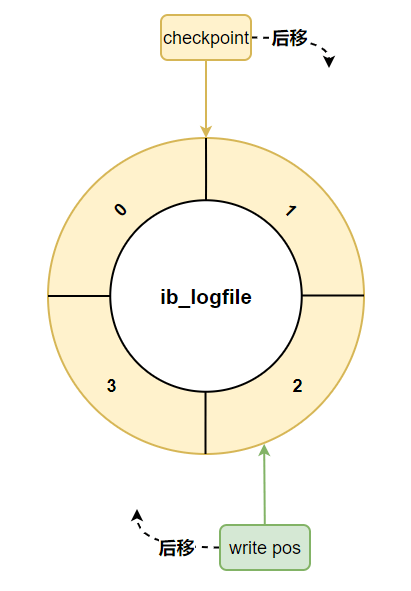
- 借助的内存空间?
redo log buffer
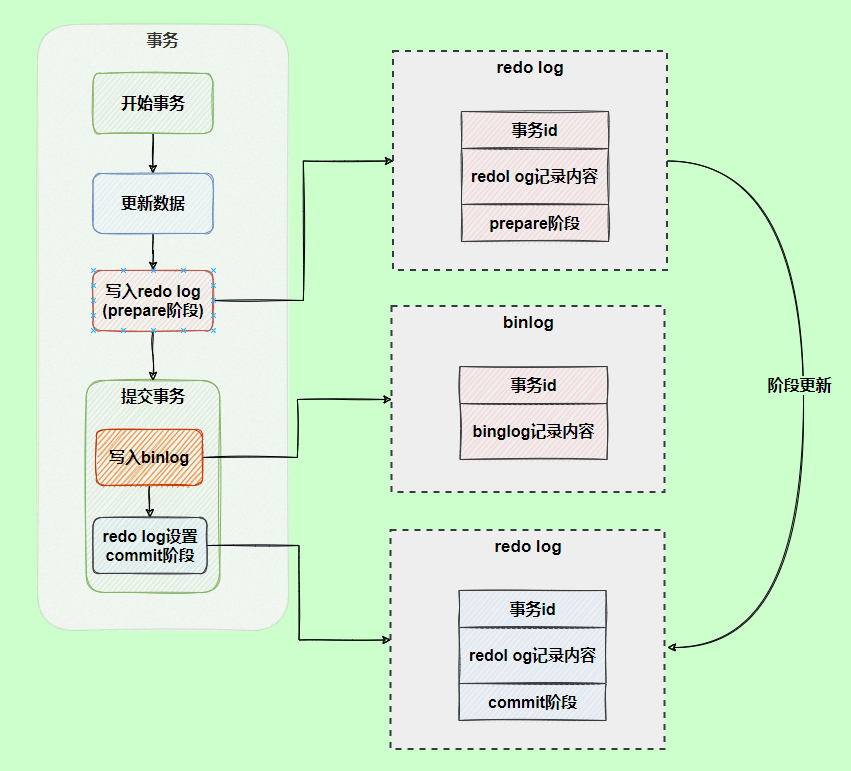
两阶段提交
- 示意图:
- 作用:
- 保证 redo log & binlog 数据的一致性,若是主从复制则主库 & 从库 数据一致
- 判断逻辑:
- prepare 阶段,redo log 写入成功,查看 binlog 状态
- undo log 完成 ==> 事务执行
- undo log 不完整 ==> 事务回滚
- commit 阶段
- binlog 肯定完成 ==> 事务执行
- prepare 阶段,redo log 写入成功,查看 binlog 状态
3) undo log
- 是什么?
- 记录数据的历史版本
- 是什么样式?
- 逻辑日志
- insert 语句对应 undo log 的 delete 日志;update 语句对应 undo log 的 相反 update 日志;delete 语句对应 undo log 的 insert 日志
- 存在于哪些存储引擎中?
- MySQL InnoDB 独有
- 什么情况下会用到?
- 事务失败后的回滚操作
- MVCC
- 文件大小?
- 参数:
innodb_max_undo_log_size
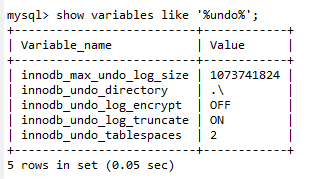
6. 其他日志
error log
- 对 MySQL 的启动、运行、关闭过程进行了记录,可以帮助定位 MySQL 问题
slow query log
- 慢查询日志
- 记录执行时间超过
long_query_time变量定义的时长的 查询语句
general log
- 记录所有对 MySQL 数据库请求的信息,无论请求是否正确执行