🪕 性能优化
2022年6月9日
- db
🪕 性能优化
1. 语句优化
1) 慢日志
- 相关参数
slow_query_loglong_query_timeslow_query_log_file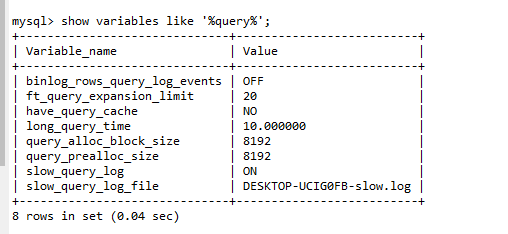
借助一些工具分析慢查询日志
- 服务监控
- 在业务中加入对 慢SQL 的监控
2) Explain
除了支持
select语句,还支持delete,update,insert,replace
① 输出格式


id- 若没有子查询 | 联合查询 [
union],id = 1 - 若存在联表查询,临时表的 id = null,table 列 = <union 1, 2>格式
- 若 id 相同,则从上到下依次执行
- 若 id 不同,则 id 大的行所在的表先执行
- 若 id 相同 + id 不同均存在,则 id 大的表先执行,遇到 id 相同的表从上到下依次执行
- 若没有子查询 | 联合查询 [
select_typesimple- 简单查询,无子查询 | union
primary - union - union result- 联合查询,第一个表示最外层查询,第二个表示 union 后的表,第三个表示联合后生成的临时表
primary - derived- 含 from 的子查询,第一个表示最外层查询,第二个表示子查询
primary - subquery- 不含 from 的子查询,第一个为最外层查询,第二个为不含 from 的子查询
primary - dependent- 关联子查询,且子查询使用了外部查询包含的列,第一个为最外层查询,第二个为内部子查询
primary - uncacheable- 不能缓存的子查询,第一个为最外层查询,第二个为不能缓存的子查询
table- 表名
- union result 的表名 == <union a, b>,derived 表名 == null
partitions- 显示分区信息,若无 == null
typesystem- 只有一条数据的系统表
const- 主键 | 唯一索引 的 等值查询,最终肯定返回一条 | 0 条记录
eq_ref- 主键 | 唯一索引 的 范围查询 & 最多返回一条记录,但通常需要扫描多次才能找到
ref- 普通索引 | 满足最左前缀匹配的联合索引 的 等值查询,返回多条记录
fulltext- 使用 FULLTEXT 索引
ref_or_null- 普通索引 的 等值查询 + or 普通索引 is null 查询
index_merge- 对于这种单表查询(无法跨表合并)用到了多个索引的情况,每个索引都可能返回一个结果,然后对总的结果取 交并集
unique_subqueryeq_ref特例 + in(select 子查询),出现在 update 语句中
index_subquery- 非唯一索引的 unique_subquery
range- 索引 的 范围查询
index- 根据 索引 顺序扫表查询
all- 全表扫描
possible_keys- 可以使用哪些索引
key- 实际使用的索引
key_len- 索引字段的最大可能长度,非实际数据的长度
ref- key 展示的索引实际使用的列 | 常量
rows- 需要读取的行数,非精确值
filtered- 符合条件的记录数占需要读取的行数的百分比
ExtraUsing index:覆盖索引Using index condition: 索引下推Using temporary: 排序使用了临时表Using filesort: 使用外部索引文件排序,无法判断是内存 | 磁盘排序,但更消耗性能是一定的Using where: 使用 where 过滤
3) 常用 SQL 规范性检查
group by&order by无法适用于前缀索引limit m, n当 n 特别大时,可采用批量处理;当 m 特别大时,也可进行以下优化:
主键索引的
limit m, n
非主键索引的
limit m, n
2. 索引优化
1) 是否需要建立索引?
- 考虑建立索引的优缺点 & 限制条件
2) 给哪些字段添加索引?
- 经常需要搜索的列
- 经常需要根据范围进行搜索的列
- 经常需要排序的列
- 区分度高
3) 添加什么类型的索引?
- 唯一索引
- 普通索引
- 联合索引
- 前缀索引
- 全文索引
4) 有效利用索引覆盖
5) 有效利用索引下推
6) 遵循最左匹配原则
3. 表的优化
4. 其他优化
1) 主从架构,读写分离
2) 集群
3) 分库分表
4) 提高机器配置
5) 异步执行
- 采用 MQ,写入 MQ 成功后即可返回
- 采用 本地内存(ConcurrentHashMap) + 定时任务,在定时任务中写入 DB
- 采用 线程池,将 写入 DB 操作放在一个单独的 线程池中