⛅ 操作系统概述
1. 计算机硬件结构
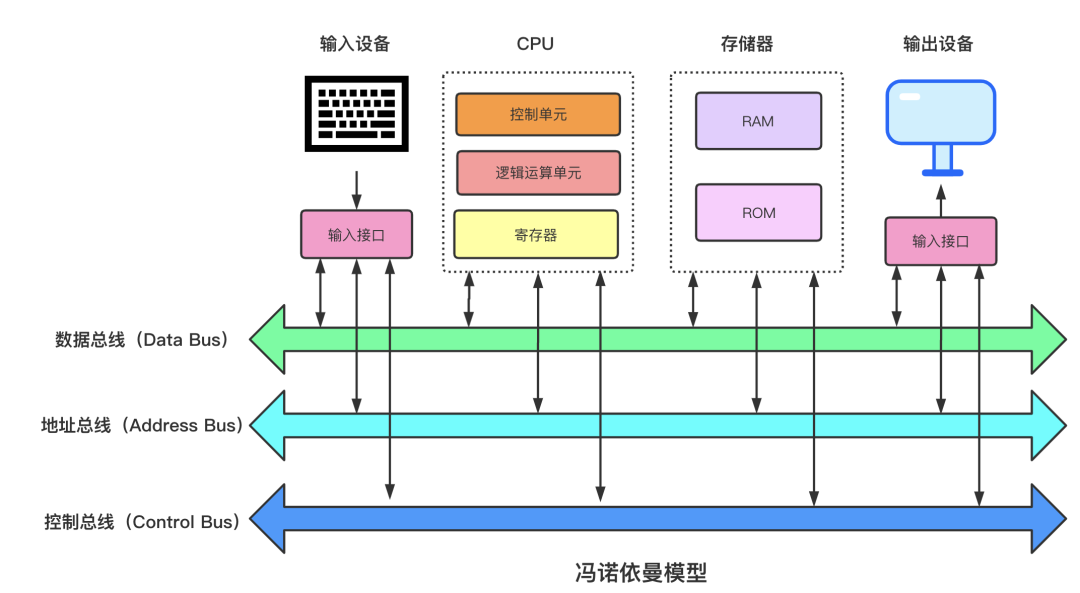
- 冯诺依曼模型 将计算机分为 5 个基本结构
- 模型图
- 流程:
CPU 读取 程序计数器,得到要执行指令的 内存地址- 通过
地址总线 获取 对应内存中的 指令数据 - 通过
数据总线 将数据 存入 CPU 的 指令寄存器 CPU 分析 指令寄存器 中的 指令, - 若是
计算 指令,交给 逻辑运算单元 - 若是
读写 等存储指令,交给 控制单元
- CPU 执行完当前指令后,
程序计数器 +4/+8 字节 更新,执行下一条指令,如此循环
1) CPU
- 中央处理器
- 包含
控制单元逻辑运算单元寄存器- 最靠近 控制单元 & 逻辑运算单元 的存储器,速度最快,一般要求在 半个 CPU 时钟周期内完成读写操作,纳秒级别,数量在 几十 - 几百 之间
- 用于保存 关键变量 & 临时结果
- 通用寄存器
- 程序计数器
- 指令寄存器
- 存储 程序计数器 要执行的指令本身,即 内存地址指向的实际指令
- PSW 程序状态字寄存器
- 维护 8 字节的当前系统状态 信息,例如当前是 用户态还是内核态
- 堆栈指针寄存器
- 指向内存中当前栈的顶端,包含输入过程中的相关参数、局部变量 & 没有保存在寄存器中的临时变量
CPU Cache
- CPU 位宽
- 每个 CPU 都有各自的 特定指令集,因此 x86 的 CPU 不能执行 ARM 程序,反之 ARM 的 CPU 也无法执行 x86 的程序
2) 存储器
3) 总线
- 负责 CPU & 内存 及 外设 之间的通信
- 分类
地址总线数据总线控制总线- 用于发送 & 接收信号,例如 中断、设备复位等信号
4) 输入设备 & 输出设备
2. 操作系统
1) 功能
- 为上层应用访问硬件设备提供桥梁,使得上层应用只需要和操作系统打交道,而无需关注各个硬件的直接调用逻辑
- 操作系统一般提供以下功能:
- 内存管理
- 文件系统管理
- 进程管理
- 硬件设备管理
- 提供系统调用
2) 分类
Linux- 多任务
- 单 CPU 下多任务并发执行;多 CPU 下可多任务并行执行
- 对称多处理
- 每个 CPU 的地位相等,共享同一内存,应用程序可分配到任意 CPU
- 宏内核
- 可执行文件格式为 ELF
- 更加安全的用户与文件权限策略
- 适合小内核程序的嵌入系统
Windows- 多任务
- 对称多处理
- 混合内核
- 内核中有个微内核,微内核可将部分功能放在用户态处理,其他核心功能放在内核态处理
- 可执行文件格式为 PE
3. 系统调用
针对 UNIX 系统
1) 用于进程管理
| 系统调用 | 描述 |
|---|
pid = fork() | 创建与父进程相同的子进程 |
pid = waitpid(pid, &statloc,options) | 等待一个子进程终止 |
s = execve(name,argv,environp) | 替换一个进程的核心映像 |
exit(status) | 终止进程执行并返回状态 |
2) 用于文件管理
| 系统调用 | 描述 |
|---|
fd = open(file, how,...) | 打开一个文件使用读、写 |
s = close(fd) | 关闭一个打开的文件 |
n = read(fd,buffer,nbytes) | 把数据从一个文件读到缓冲区中 |
n = write(fd,buffer,nbytes) | 把数据从缓冲区写到一个文件中 |
position = iseek(fd,offset,whence) | 移动文件指针,这样可以从文件的任意位置开始,whence 表示是从前往后还是从后往前移动 offset |
s = stat(name,&buf) | 取得文件状态信息 |
3) 用于目录管理
| 系统调用 | 描述 |
|---|
s = mkdir(nname,mode) | 创建一个新目录 |
s = rmdir(name) | 删去一个空目录 |
s = link(name1,name2) | 创建一个新目录项 name2,并指向 name1 |
s = unlink(name) | 删去一个目录项 |
s = mount(special,name,flag) | 安装一个文件系统 |
s = umount(special) | 卸载一个文件系统 |
4) 其他
| 系统调用 | 描述 |
|---|
s = chdir(dirname) | 改变工作目录 |
s = chmod(name,mode) | 修改一个文件的保护位,每个文件均有 读 - 写 - 执行 权限 |
s = kill(pid, signal) | 发送信号给进程 |
seconds = time(&seconds) | 获取从 1970 年 1 月 1 日至今的时间 |
4. 其他问题
1. 存储相关层次结构
- 寄存器
- CPU Cache
SRAM - 静态随机存储器,断电数据丢失- L1 Cache
- 每个 CPU 核 独有
2 - 4 个时钟周期,几十 - 几百 KB 空间大小- 查看空间大小指令
cat /sys/devices/system/cpu/cpu0/cache/index0/size 数据缓存大小cat /sys/devices/system/cpu/cpu0/cache/index1/size 指令缓存大小
- L2 Cache
- 每个 CPU 核 独有
10 - 20 个时钟周期, 几百 - 几千 KB 空间大小- 查看空间大小指令
cat /sys/devices/system/cpu/cpu0/cache/index2/size
- L3 Cache
- 所有 CPU 核 共用
20 - 60 个时钟周期,几 - 几十 MB 空间大小- 查看空间大小指令
cat /sys/devices/system/cpu/cpu0/cache/index3/size
- 内存
DRAM - 动态随机存储器,需定时刷新电容保证数据不丢失,断电数据丢失,速度比 SRAM 慢- 所有 CPU 核 共用
200 - 300 个时钟周期
- 硬盘
- 固态硬盘 SSD
- 断电数据不丢失
- 比内存速度慢
10 - 1000 倍 - 不是磁盘,也没有可以移动的部分,外形也不像唱片,数据存储在
闪存 中,与磁盘唯一相似之处在于 断电数据不丢失
- 机械硬盘 HDD
- 访问顺序
- 每一层存储结构只会与相邻层打交道,而不会跳过相邻层,直接与隔代层打交道
2. Cache Line 缓存行
CPU Cache 与内存打交道的过程中,从内存读取数据,是以 缓存行 [Cache Line] 为单位操作的Linux 中 缓存行 大小 = 64 B == 8 个 long 型基本变量 - 查看指令
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
- 缓存行 中保存哪些信息?
- 设内存块数量为 N,缓存行数量为 M
Cache Line Index- 判断某个内存块 x 是否存在于缓存行中,只需要找下标 index = x % M 处是否存在该内存块数据,因此多个内存块可能映射到一个缓存行中,要区分,还需要其他标志位
- 引入 组标记 [
Tag] - 记录当前 Cache Line 下标处
Tag 对应的是哪一个内存块,这样即使多个内存块映射到同一缓存行,也可以通过 Tag 区分
- 有效位标识符 [
Valid Bit] - == 0 时表示无论缓存行中是否存在该内存数据,CPU 都直接访问内存,重新加载数据
- 实际数据 [
Data]
- CPU 要定位到 具体缓存行中需要包含:
Cache Line IndexTagOffset- 定位到该缓存行的读取片段,要知道每次读取不是直接读取整个缓存行数据的,而是读取该缓存行的一部分
- CPU 写入数据时,假设存在于 CPU Cache中,将数据写入 缓存行 后,什么时候将数据刷回内存?
- 写直达
- 若数据存在于 CPU Cache,修改对应 缓存行数据 的同时,还需要修改内存对应数据
- 若数据不存在于 CPU Cache,修改内存数据
- 特点:
- 每次操作 CPU Cache 时,同时还需要操作内存,效率较低
- 写回
- 若数据存在于 CPU Cache,只需要修改对应 缓存行数据 的某个部分,同时标记为 脏块,表示该块 CPU Cache 和 内存对应数据不匹配
- 若数据不存在于 CPU Cache,定位到该 缓存行,判断是否存在脏块
- 若存在脏块,将 缓存行数据 对应块数据 刷回 内存;将要写入的数据,从内存中读入该 缓存行 对应块位置,修改该缓存行数据块为要写入的数据,同时标记为脏块
- 若不存在脏块,将要写入的数据,从内存中读入该 缓存行 对应块位置,修改该缓存行数据块为要写入的数据,同时标记为脏块
- 特点:
- 缓存命中率高时,只需要修改 CPU Cache,无需操作内存,效率提高
3. 如何提高 CPU 访问速度?
- 可以看到,从 寄存器 - CPU Cache - 内存 - 硬盘,CPU 访问速度依次递增
- 因此,当与硬盘交互时,可以尝试利用 内存 提高速度
- 当与内存打交道时,可以尝试利用 CPU Cache 提高速度,即提高 CPU 缓存 的 缓存命中率
4. 如何充分利用 CPU Cache?
- 提高
数据缓存 的命中率 - 遍历数据时,尽可能按照内存布局顺序访问,这样 缓存行 一次加载的就是连续的相邻数据,命中率高
- 提高
指令缓存 的命中率 - CPU 自带 分支预测器,当使用
if() 语句时,若在某个循环里,if() 经常命中,则会缓存if() 里的指令
- 提高
多核CPU 的命中率 - 多核 CPU 中,一个线程可能在不同的时间片中使用不同的 CPU 核心,
- 就导致前一次的线程数据缓存在 CPU 核1 对应的 L1 & L2 Cache 中,
- 下一次切换到 CPU 核2 后,CPU 核1 保存的数据就无效了
- 可通过 线程 与 CPU 核 进行绑定,使得 某个线程 一直使用 特定 CPU 核,从而提高缓存命中率
5. 缓存一致性问题
- 为什么会出现缓存不一致的情况?
- L1 Cache & L2 Cache 是 CPU 核 各有的
- 那么多线程运行时,线程 1 操作 CPU 核1,线程 2 操作 CPU 核2,数据刷回主存采用的是 写回 策略
- 当线程 1 & 线程 2 均需要执行 i ++ 操作时,
- 线程 1 读取主存中 i 初始值 0, 执行 i ++,将数据写入 CPU Cache,标记为脏块,但未刷回主存
- 线程 2 同样读取主存中 i 初始值 0, 执行 i ++,将数据写入 CPU Cache,标记为脏块,但未刷回主存
- 理论上,最终 i == 2,但是由于 CPU Cache 这种机制,导致了 i 并不一定 == 2,从而出现结果计算错误的问题
- 如何解决?
- 写传播
- 含义:当某个 CPU 核中的 Cache 数据更新,需要保证其他 CPU 核 可以收到该变化通知
- 实现方式:
- 总线嗅探:
- 原理:每个 CPU 核均需要监听总线上的广播事件;当某个数据在某个 CPU 核发生改变时,其他 CPU 核收到通知后,需要查看自己是否有该数据,如果有,需要更新自己的对应数据
- 特色:
- 方法简单
- 但需要时刻监听总线上的所有广播事件,无论自己是否有该数据
- 串行化
- 含义:所有 CPU 核收到的某个数据的变化顺序必须一致
- 如何实现:前提要做到 写传播,然后通过 锁 的方式实现,基于 总线嗅探 的 MESI 协议 就是具体实现
6. 伪共享问题
- 产生原因
- 一个缓存行假设大小为 64KB,如果单个变量大小达不到这个值,就可能导致 缓存行 中存储的是 多个内存相邻的变量值
- 当多线程下,同时操作同一缓存行下的不同变量时,由于
MESI 协议机制,就导致达不到 CPU 缓存的效果,该缓存行会一直处于失效状态,性能降低
- 流程分析
- 假设 有
2 个相邻的变量 x & y,一个缓存行就可以放得下这 2 个变量 - 假设 有
2 个线程,线程 1 操作 x 变量,线程 2 操作 y 变量 - 初始时,线程 1 和 线程 2 对应的 CPU 核中均不存在对应变量数据,变量数据只存在于 内存中
- 当 线程 1 读写 变量
x 时,线程 1 某缓存行加载进了 x & y,此时该缓存行状态为 E; - 当 线程 2 读写 变量
y 时,线程 2 某缓存行加载进了 x & y,此时所有拥有该数据的 CPU 核对应的该缓存行状态为 S; - 当 线程 1 修改 变量
x 时,通过 总线 让所有 CPU 核对应的该数据的缓存行 状态变更为 I,然后 线程 1 修改 该缓存行的 x,线程 1 该缓存行状态变为 M,未刷回主存 - 当 线程 2 修改 变量
y 时,由于 该缓存行 状态为 I,因此从 主存读,由于 某 CPU 核该缓存行状态为 M,因此需要先将 数据从某 CPU 核中刷回主存,读入 线程 2 所在 CPU 核后, - 修改 变量
y 时,通过 总线 让所有 CPU 核对应的该数据的缓存行 状态变更为 I,然后 线程 2 修改 该缓存行的 y,线程 2 该缓存行状态变为 M,未刷回主存
- 可以看到,若 2 个线程频繁交替修改各自变量,会重复将 缓存行失效 --> 刷回主存 --> 从主存读取 --> 将缓存行失效 如此循环,
- 一直和 内存 打交道,CPU 缓存就相当于一直没有利用的状态,影响性能
- 而我们希望 线程 1 操作 x 时,变量 y 并未失效,线程 2 可以直接从缓存行中读取该数据,2 个变量不会相互影响,拖慢性能
- 如何解决
- 对其填充,让每个变量单独占据整数倍的缓存行,以空间换时间
@sun.misc.Contended 注解,会增加128字节的 padding,并且需要开启 -XX:-RestrictContended 选项后才能生效 LogAdder 的 Cell 类就采用了 该注解
7. 中断
- 中断请求的处理函数必须 足够短 & 快
- 在执行中断处理函数的过程中,不会响应其他中断请求,为防止在执行过程中丢失其他中断请求,因此必须 短 & 快
- Linux 为了解决中断处理程序执行过长 | 中断丢失问题,将中断分为 2 个过程:
- 前半段 - 硬中断
- 后半段 - 软中断
- 主要处理上半段未完成的请求 & 内核自定义事件,由内核触发,通常为 耗时长且可延迟执行 的任务
8. 硬实时 VS 软实时
- 硬实时系统
- 软实时系统
- 虽然不希望某个动作没有在规定的时刻发生,但仍可以接受该结果,并不会有太大损害
- 例:数字音频、多媒体系统、智能手机