☁️ 内存管理
2022年10月10日
- os
☁️ 内存管理
1. 内存分段
1) 8086 分析
- 8086 中,寄存器为
16位,地址总线为20位,可寻址地址空间大小 == 2^20 Byte == 1 M - 如何通过 16 位寄存器得到 20 位的地址空间?
- 将 1 M 的地址空间分成 16 个 64 KB 的段
- 这样每个段就是 16 位,可以用一个寄存器的值来表示
- 16 个段中,有 4 个段我们最关心,它们分别存放在以下四个寄存器中,即:
- 代码段
CS - 数据段
DS - 堆栈段
SS - 附加段
ES
- 代码段
- 20 位地址空间 = (CS | DS | SS | ES) <<< 4 + 段偏移量 [IP 寄存器中]
- 可以看出,寄存器中保存的还是实际的物理地址数据,而寄存器的值可以被用户随意改变,因此容易发生数据的覆盖,这种寻址模式称为实模式
2) 80286 分析
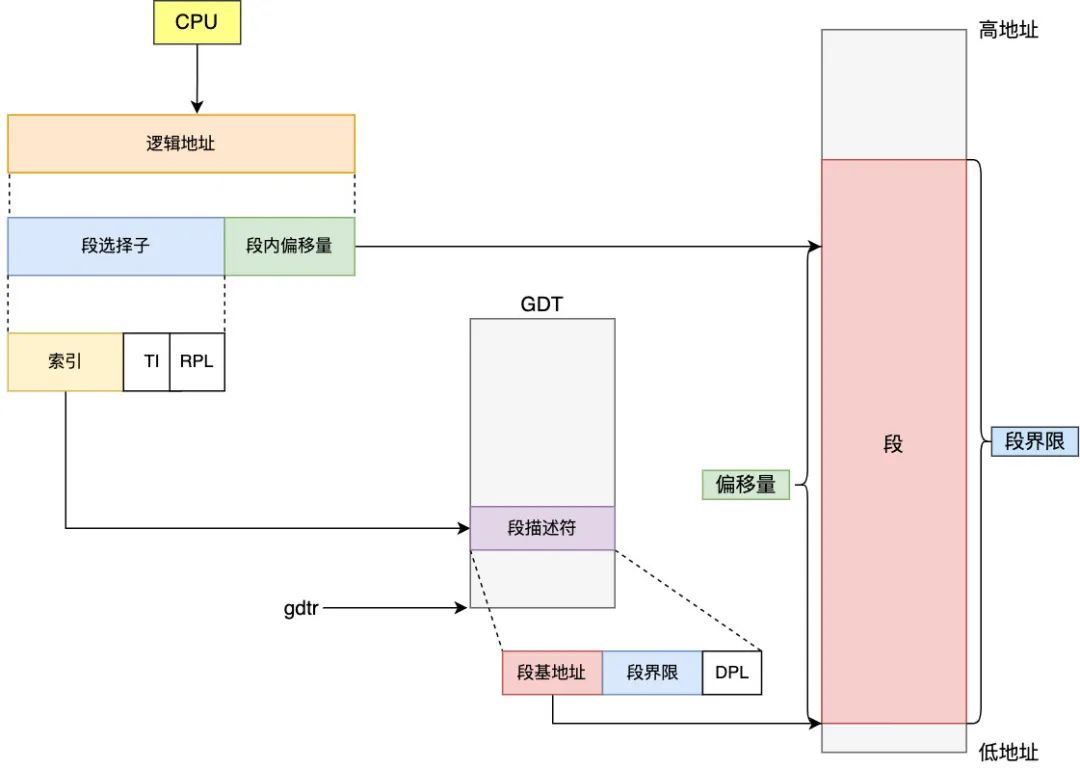
- 80286 启用了保护模式,该模式下,
- 段寄存器保存的是段选择因子,段选择因子中保存了段表索引,段表记录了多个段描述符
- 每个段描述符中记录了段基址 & 段长度,段描述符由操作系统管理,进程无法更新 CS 等寄存器的值,从而保护了内存数据的安全
(段基址 + 保存在 IP 寄存器中的偏移量) [称为 逻辑地址] == 物理地址
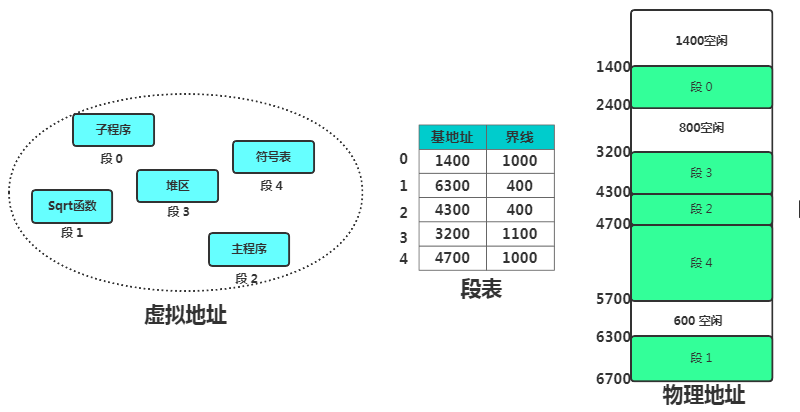
3) 内存分段
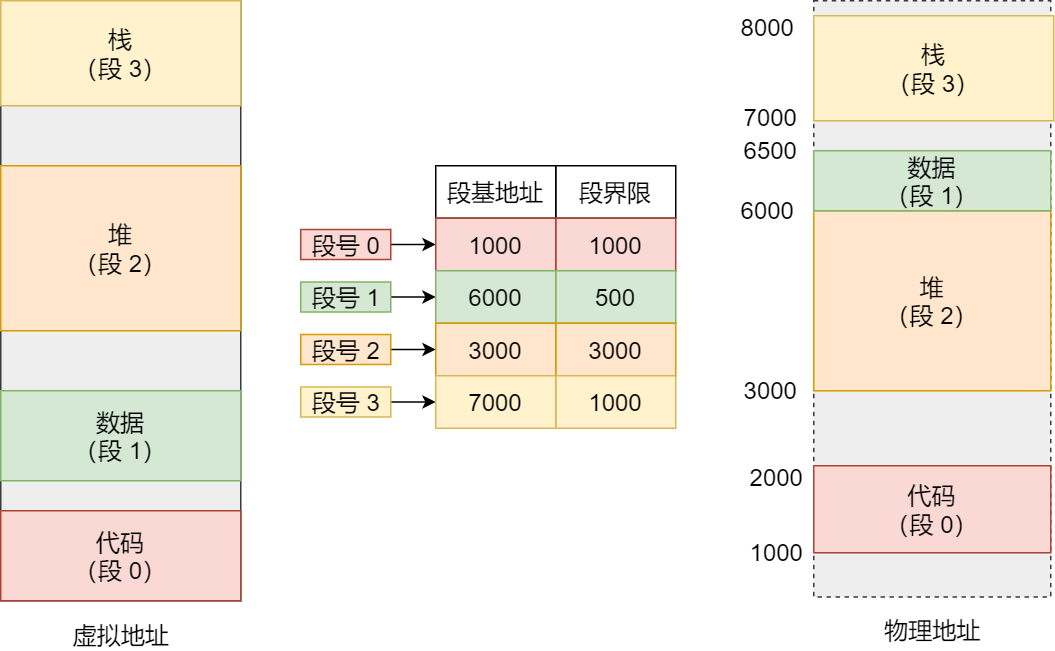
- 将内存分为不同的段,例如代码段、数据段、堆段、栈段等
- 每个段占据一定的内存空间,各有段基址
- 当一个程序在运行时,虚拟地址由 段选择因子 & 段偏移量决定
- 段选择因子:
- 保存在段寄存器中
- 里面保存了段号、特权等标志位
- 程序通过段选择因子中的段号可以到段表中查询这个段的段基地址、段界限、特权等级等
- 段选择因子:
4) 优缺点
- 优点:
- 程序不用参与物理地址的分配,也无需考虑地址冲突、覆盖问题,一切由操作系统完成
- 即使虚拟地址相同,只要操作系统保证映射到不同的物理地址即可,让多线程运行成为可能
- 缺点:
- 容易产生内存碎片,段氏内存需要分配连续的内存空间
- 当内存分配不足时,触发内存交换 [
swap]- 内存交换频率较高,会频繁的和磁盘换入换出,
- 且每次交换,都是以程序运行所用所有内存为单位
- 系统性能受到影响
2. 内存分页
1) 80386 分析
- 80386 为
32位处理器,也是首个支持分页的 CPU,在段式管理的基础上进行分页
2) 内存分页
- 将虚拟内存 & 物理内存均切成一个个固定尺寸的页
Linux中 页 size == 4 KB == 2^12 Byte
- 虚拟内存地址 和 物理内存地址的映射关系,靠 页表 维护
- 页表中保存 虚拟地址页号 - 物理地址页号 的对应关系
- 虚拟内存地址中保存 页号 + 页内偏移
(页号 + 页内偏移 ) [称为 **线性地址**]=> 物理地址
- 单级页表计算问题:
- 假设操作系统由
32位虚拟地址,那么可表示的 内存 == 2^32 Byte = 4 GB - page = 4 KB = 2^12 Byte
- 所以,需要的总页表记录条数数 total = 2^20
- 假设 页表中记录 一条 虚拟地址页号 - 物理地址页号 的对应关系 需要 4 Byte
- 那么记录所有页表项需要的内存大小
- = (2^20) * 4 Byte
- = 2^10 * 2^10 * 4 B
- = 2^10 B * 2^10 * 4
- = 1 KB * 2^10 * 4
- = 2^10 KB * 4
- = 1 MB * 4
- = 4 MB
- 假设现在有
100个进程正在运行,每个进程均有自己的页表维护空间,维护所有页表项中 虚拟地址页号 - 物理地址页号 的对应关系 - 则 此时光维护页表就需要占用 400MB 的空间
- 假设操作系统由
3) 多级页表
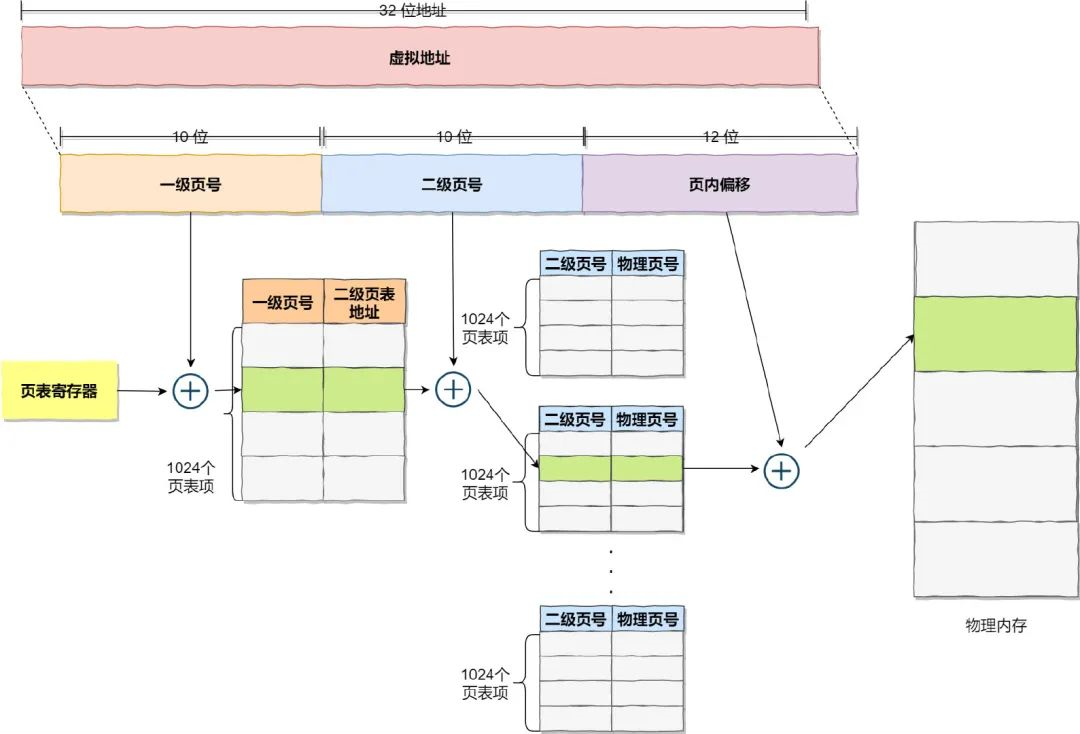
- 同样的问题再次计算:
- 将 1 级页表分为 2 级页表,每级页表占用
10位,也就是最多记录 2^10 = 1024 条记录 - 一级页表记录 1024 条记录,每条记录记载 一级页号 - 二级页表地址 对应关系
- 二级页表记录 1024 条记录,每条记录记载 二级页号 - 物理页号 对应关系
- 一级页表的一条记录的 1024 条对应二级页表地址都记录满了后,才开启下一条一级页表的记录
- (这里的意思是创建该条对应的二级页表,但一级页表所占空间还是那么大,只是数据==空)
- 所有进程均需维护一级页表的所有记录,即占用内存空间 == 2^10 * 4 B =
4 KB - 由于一个进程不可能占用全部 4 GB 的虚拟地址,因此一级页表不可能写满,达到 1024 条
- 现假设一个进程的一级页表空间被写入二级记录的比例 =
20% - 那么一个进程需要记录的关于页记录的 内存空间
- = 一级页表空间 [
4 KB] + 二级页表空间 [0.2 * 4 MB,只有被使用才会有对应的二级页表空间] - =
0.848 MB < 4 MB
- = 一级页表空间 [
- 假设现在有
100个进程正在运行,则 此时维护页表需要占用 84.8MB 的空间,比原来节约了不少内存空间
- 将 1 级页表分为 2 级页表,每级页表占用
- 对于 64 位系统,分成了 4 级页表,如下所示:
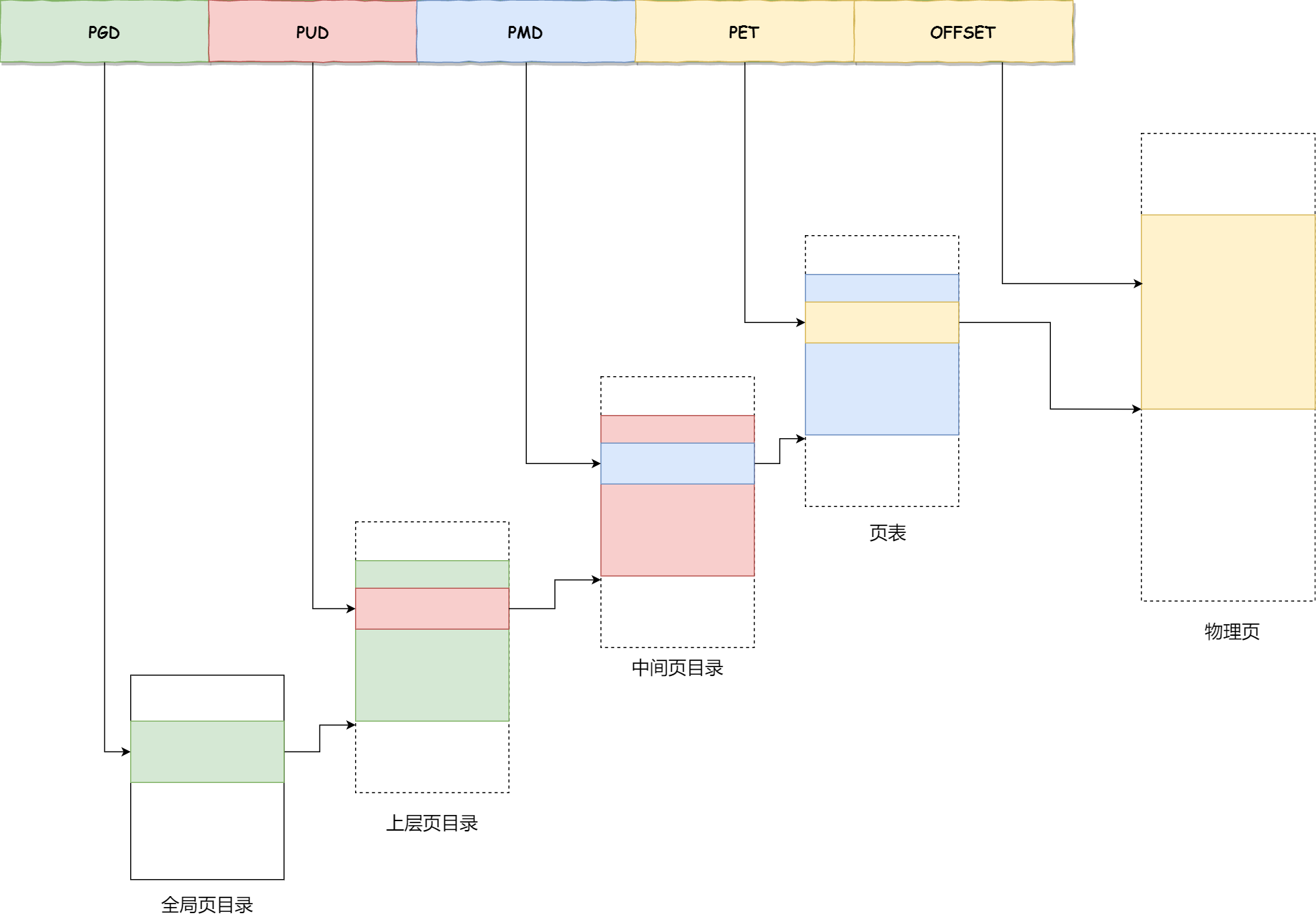
- 全局页目录项 [
Page Global Directory] - 上层页目录项 [
Page Upper Directory] - 中间页目录项 [
Page Middle Directory] - 页表项 [
Page Table Entry] - 偏移量 [
Offse]
- 特点:
- 节约页表维护的内存空间
- 增加了页表查找的转换工作,增大时间开销
4) 快表
- 将频繁使用的几个页表项记录到 CPU 芯片中的某个位置,这个位置被称为
TLB,也叫快表 - CPU 通过 内存管理单元 [MMU] 完成地址的转换工作 & 与 TLB 的交互 & 访问
- CPU 在寻址时,首先查找
TLB中是否存在该虚拟页号对应的物理页号- 如果存在,直接返回
- 如果不存在,查询多级页表
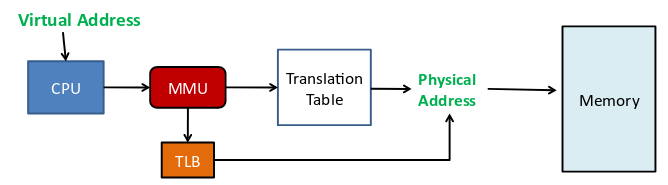
TLB的刷新- 当发生进程的上下文切换时,需要刷新 TLB,因为 TLB 中保留的多数是当前进程的快表数据
- 全部刷新
- 简单但花销大,造成可能有用的数据也进行了刷新
- 部分刷新
- 根据标志位,刷新需要刷新的数据,保留不需要刷新的数据
5) 优缺点
- 优点:
- 不会产生内存碎片
- 内存已经被分为一个个页,不存在碎片,只会有是否被使用的区别
- 内存交换频率 & 交换大小 降低,性能提高
- 只有当某个进程所需内存不够时,进行换入 & 换出,而且不是整个进程所有内存地址均需要使用,而是只交换该进程需要运行的那部分地址所对应的页
- 不会产生内存碎片
6) MMU
MMU内存管理单元- 功能:
- 将虚拟地址转换为物理地址
- 实现内存保护
- 对中央处理器高速缓存 - 快表 的控制
3. 段页式管理
1) 如何实现
- 先分段,将程序分为多个段,例如程序段、数据段、堆栈段等
- 再分页,将每个段分为多个大小固定的页
2) 表示方式
- 地址 = 段号 + 段内页号 + 页内偏移量
3) 如何访问
- 访问段表,得到页表起始地址
- 基于页表起始地址 & 段内页号,得到物理页号
- 基于物理页号 & 页内偏移量,得到物理地址
逻辑地址 VS 线性地址
- 逻辑地址:
- 被段式内存管理映射的地址,例如
段号 : 偏移量
- 被段式内存管理映射的地址,例如
- 线性地址:
- 被页式内存管理映射的地址,例如
页号 : 页内偏移量
- 被页式内存管理映射的地址,例如
4. Linux 内存管理
1) 段页式管理
- Linux 系统是基于 X86 CPU 而做的操作系统,由于 该 CPU 通常采用段页式管理,所以 Linux 也采用 段页式内存管理方式
- Linux 中每个段的的起始地址均从 0 开始,覆盖整个虚拟内存空间
- 从这个程度上来说,相当于段发挥的作用已经不存在,只被用于访问控制 & 内存保护
- 要找到对应的物理地址,只需要借助 页号 + 页内偏移,段号对应的页表起始地址恒 == 0
2) 虚拟内存空间分布
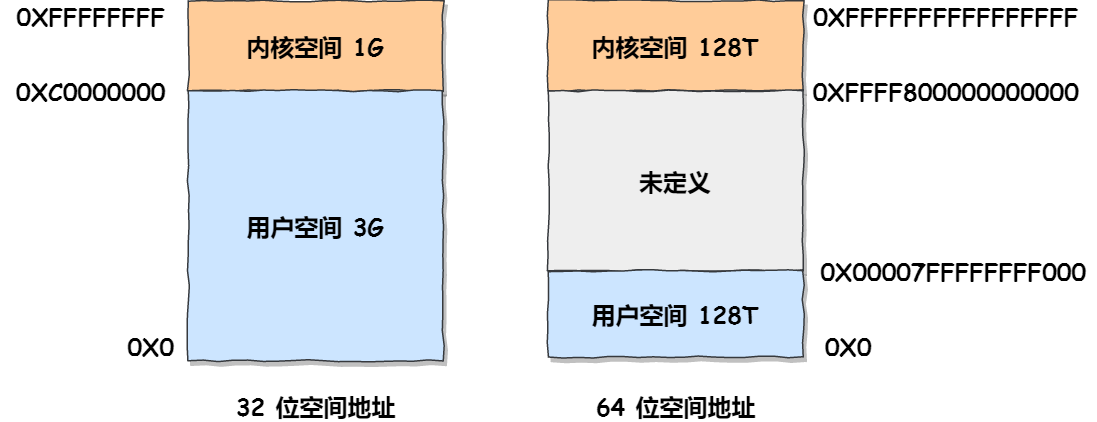
用户空间内存分布 [32 位系统 ]:
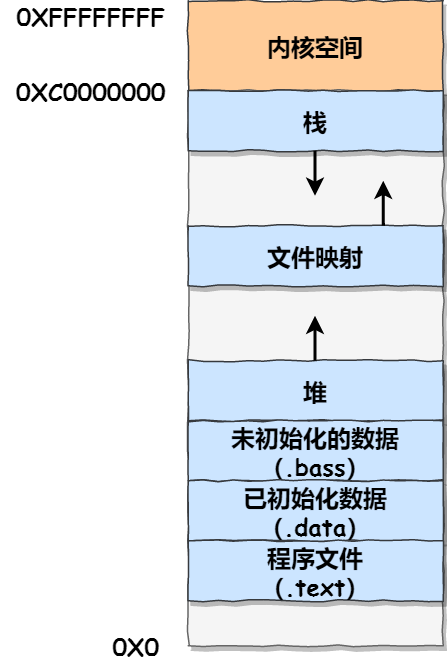
- 栈的大小一般固定为 8 MB,但也可以调节其大小
- 栈、文件映射、堆处于动态分配
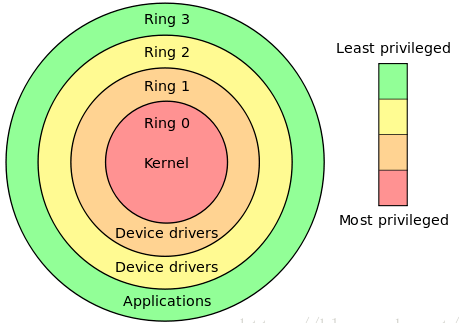
3) 内核空间 & 用户空间
- 内核空间
- 只能由操作系统的内核访问,普通用户程序不可直接访问,内核态下 CPU 可执行任何指令,可以访问任何有效地址
- 用户空间
- 普通用户程序可以访问的内存区域,有关指令 & 可访问空间受到限制
- 为什么要区分成 2 个空间?
- 对应单用户、单任务的操作系统,没有区分内核态 & 用户态的必要
- 为了满足 多用户、多任务的要求,让不同用户、不同程序代码有不同的权限,防止操作系统的核心底层代码 & 其他用户数据被无意 | 恶意更改
5. malloc() & free()
1) malloc() 分配方式?
- 分配的什么内存?
- 虚拟空间内存
- 若是分配的虚拟空间内存没有被访问,则不会映射到物理内存
- 只有真正被访问时,发现该虚拟空间内存对应的页没有存在于物理内存中,才会触发缺页中断,进而进入内核空间分配物理内存,更新页表,返回用户空间,恢复进程的执行
- 2 种方式
brk()- 发起系统调用,分配堆内存
- 当用户分配空间 < 128 KB 时 [与版本有关,不同版本可能不同]
mmap()- 发起系统调用,分配文件映射区内存
- 当用户分配空间 > 128 KB 时
- 申请多大 == 实际分配多大吗?
- 实际分配空间 > 申请空间
2) free() 回收方式?
- 2 种态度
- 对于
malloc()通过brk()分配的堆内存,不会归还操作系统,而是缓存在malloc的内存池中,方便复用- 该方式
free()后的内存池基本连续,因此不会频繁发生缺页中断,效率高 - 进程退出后,操作系统会回收该进程的所有资源
- 该方式
- 对于
malloc()通过mmap()分配的文件描述符内存,会归还操作系统,内存得到真正释放- 该方式
free()后,会导致文件描述符一块一块的,发生缺页中断的频率较高
- 该方式
- 对于
- 符合通过只传入内存地址,就知道释放多大空间?
- 操作系统分配内存时,还会多分配一部分空间,用于记录该空间的大小等信息
- 在调用
free()后,可以读取到回收空间的大小,进而根据内存地址 & 空间大小,进行释放
6. 内存分配
1) 物理内存分配过程
- 通过
malloc()函数等分配的是虚拟内存,当被访问到时发现没有对应的物理页,- 就会发生缺页中断,由用户态切换到内核态,
- 由缺页中断函数 进行 物理内存的分配
- 分配流程如下:
- 查看是否有空闲的物理内存
- 有,则将该空闲物理内存分配给需要的虚拟内存,更新页表,返回用户态
- 无,则进行物理内存的回收,首先触发后台内存回收 [
kswapd],该回收操作为异步过程,且为 守护进程,不会阻塞进程的执行- 后台内存回收后,
- 若产生空闲物理内存,则分配给需要的虚拟内存,更新页表,返回用户态
- 若还是没有足够的物理内存,则触发直接内存回收,该回收操作为同步过程,会阻塞进程的执行
- 若产生空闲物理内存,则分配给需要的虚拟内存,更新页表,返回用户态
- 若还是没有足够的物理内存,则触发 OOM 机制,产生空闲物理内存
- 后台内存回收后,
- 查看是否有空闲的物理内存
- 怎么判断是否有空闲的物理内存?
- 内存定义了 3 个内存阈值
- 当
∈ [页高阈值, +∞]时,说明物理内存足够 - 当
∈ [页低阈值, 页高阈值]时,说明物理内存分配正常 - 当
∈ [最小阈值, 页低阈值]时,说明物理内存压力大,此时触发异步的后台内存回收 - 当
∈ [0, 最小阈值]时,说明内存不足,此时触发阻塞的直接内存回收
- 回收哪些内存?
- 文件页
- 内核缓存的磁盘数据 & 内核缓存的文件数据
- 没有被修改过的数据页可以直接被释放
- 被修改过的脏页数据,需要首先刷入磁盘后,才可以进行内存释放
- 匿名页
- 这部分内存很有可能会被再次访问,没有实际载体,例如进程的 堆、栈 数据
- 通过
swap机制,将不常用的内存换出到磁盘,然后释放这部分内存 - 当需要再次访问时,从磁盘中换入
- 基于
LRU算法 - 除了 文件页的干净页可以直接回收,其余操作均涉及磁盘,因此性能受到影响,直接表现为系统的卡顿
- 由于文件页的回收部分不需要涉及磁盘操作,因此效率会高一些,可以通过调大文件页的回收倾向进行优化
- Linux 相关参数
/proc/sys/vm/swappinessdefault = 60 - 数值越大,越倾向于使用 swap,即回收匿名页
- 可以设置 == 0,表示更倾向于回收文件页,但并不代表不会回收匿名页
- Linux 相关参数
- 文件页
- OOM 机制
- 根据某个算法选择评分最高的进程,将其杀死,以释放内存空间
- 若释放的内存空间,仍不足以申请所需虚拟内存,则继续选择相关进程,将其杀死,直到物理内存足够分配所需
- 算法:
- 基于 Linux 内核的
oom_badness()函数实现 - 得分
points = process_pages [该进程已经使用的物理内存页面数] + oom_score_adj [校准值,用户可以设置某个进程的该参数值,属于 [-1000, 1000]] * totalpages / 1000 - 若不想某个进程被很快杀死,可以调制该进程的
oom_score_adj == -1000,通过/proc/[pid]/oom_score_adj进入调整
- 基于 Linux 内核的
2) 请求分配大内存
32位操作系统,内核空间占1G,用户空间占3G,最多可以申请3G 的虚拟内存,当内存超范时,将申请失败64位操作系统,内核空间占128T, 用户空间占128T,最多可以申请128T 的虚拟内存- 假设申请
16G 的虚拟内存,则可以申请成功 - 当虚拟内存申请成功时,读写该虚拟内存需要物理内存
- 假设物理内存
4G,此时虚拟内存 > 物理内存- 若开启
swap机制,程序可以正常运行 - 若未开启
swap机制,程序将 OOM,无法运行
- 若开启
- 假设物理内存
- 假设申请
3) swap 机制
- 是什么?
- 换入 [
swap in] 在进程需要访问被换出到磁盘的数据页时,需要将这些数据从磁盘页读入到内存 - 换出 [
swap out] 将进程暂时不需要的内存数据存储到磁盘中,并释放这部分的内存数据
- 换入 [
- 作用
- 可以使用比物理内存更大的内存
- 频繁换入换出,磁盘的读写操作将影响性能
- 什么情况下发生?
- 内存不足
- 内存闲置,触发后台、异步、守护进程的后台内存回收
- 作用于什么类型的数据页?
- 文件页
- 匿名页
7. 页面置换算法
缺页中断
- 什么情况下发生?
- 当 CPU 访问的页面不在内存中时,说明可能被 换出 到了磁盘中,此时会触发 缺页中断,通知 CPU
- 发生后,处理流程是怎么样的?
- CPU 访问页面时,首先查看 快表中是否存储了对应的页表项记录,若没有,查找多级页表找到对应的页表项记录,查看页表项记录中的 状态位 这一栏是否显示有效
- 若有效,说明存在于物理内存中,可以直接到物理内存中找到该页的数据
- 若无效,说明该页当前不存在于物理内存中,发出 缺页中断
- 操作系统收到 缺页中断 后,执行对应中断处理函数
- 通过页表项中的 硬盘地址 找到在磁盘中的位置
- 尝试将该页 换入 到物理内存中
- 若物理内存存在空闲页,则可以直接换入到物理内存,更新该页的页表项的 状态位
- 若物理内存当前不存在空闲页,则需要通过 页面置换算法,将物理内存中的某个物理页换出到磁盘,更新 页表项中的 状态位, 来为请求的缺页提供空间
- 查看换出的物理页的页表项的 修改位,判断是否被修改过,
- 若被修改过,则说明是脏页,需要重新刷盘
- 若没有修改过,由于内存中的所有页均在磁盘中有副本,因此不需要特意刷盘,可以用之前存在磁盘中的数据
- 查看换出的物理页的页表项的 修改位,判断是否被修改过,
- 将请求的缺页 换入到 物理内存中,更新该页的页表项的 状态位
- CPU 重新执行导致缺页异常的 指令
- CPU 访问页面时,首先查看 快表中是否存储了对应的页表项记录,若没有,查找多级页表找到对应的页表项记录,查看页表项记录中的 状态位 这一栏是否显示有效
- 页表项

- 状态位
- 判断该页是否有效,若有效,则说明存在于物理内存中;若无效,说明被换出到了磁盘
- 访问字段
- 记录该页在一段时间内的访问次数,页面置换算法时有的算法会用到
- 修改位
- 判断该页距离上次刷盘后,是否有修改过;若有新的修改,那么该页被换出时,需要重新刷盘;若没有修改,则无需刷盘
- 硬盘地址
- 该页在磁盘上的地址,通常为物理块号
1) 最佳页面置换
- 计算出当前哪个页面在未来时间内,最久不会被访问到的页面
- 由于用户程序访问的页面实时变动,无法准确预知,没有理论的算法可以计算出
- 因此该算法 存在的作用是,用来衡量其他页面置换算法的效率,越接近该算法的效率,说明选取的页面置换算法效果越好
2) FIFO
- 所有页面形成一条单向链表的类似状态,每次换出链表头结点对应的页面
- 特点:
- 有的页面虽然一早就存在,但也许是一直被使用到的页面
3) LRU
- 所有页面形成链表的类似状态,页面每次被访问到,就放入最后,表示最新,这样被换出的就是该段时间内最久没有被访问到的页面
- 特点:
- 所有页面组成一条链表,每次访问某一页,均需要更新整条链表,维护开销大
4) LFU
- 每个页面维护各自的计数器记录访问次数,所有页面根据频次形成各自的链表类似结构,页面每次被访问到,频次 ++,每次换出的是访问频次最小的页面
- 存在的问题:
- 维护计数器开销大
- 只考虑了频次
- 若是某个页面历史时间内频繁访问,导致频次特别大,但是最近一直没有被访问到,理应被换出,而实际没有换出
- 若是某个页面最近频繁被访问,但是之前没有被访问过,导致被换出的一直的当前页面,然后再重新进来,又相当于一个新的页面
- 如何解决
- 加上时间变量,比如说,定时将当前访问次数 除以 2,这样过了足够长时间后,某个历史页面的访问次数会一直减少,有利于被换出
5) 时钟页面置换
- 所有页面保存在一个类似时钟的环形链表中,钟表指针指向最久未被访问的页面
- 当指针指向的页面,访问次数为 0 时,说明该页可以被换出,将新页面插入到该页,指针走一位
- 当指针指向的页面,访问次数为 1 时,将访问位置零,指针走一位,循环查找,直到找到下一个访问次数为 0 的页面