🌩️ 输入输出管理
2022年10月10日
- os
🌩️ 输入输出管理
1. 设备控制器 & 驱动程序
1) 输入输出设备分类
- 块设备
- 数据存储在固定大小的块中,每个块均有自己的物理地址,传输数据也以连续的块为单位,每个块相对独立,可以单独进行读写
- 例如:硬盘、U盘
- 该类设备通常传输的数据量会很大,因此对应的 设备控制器 中会有一个 可读写 的 数据缓冲区
- 数据缓冲区的作用:提供缓冲,当数据量达到缓冲区一定程度后才会进行数据的传输
- CPU 如何与 数据缓冲区 通信?
- IO 端口
- 每个控制寄存器被分配一个 IO 端口,可以通过特殊的汇编指令操作这些寄存器
- 内存映射 IO
- 将所有控制寄存器映射到内存空间,可以像读写内存一样读写数据缓冲区
- IO 端口
- Linux 为屏蔽不同块设备的差异,引入了 通用块层
- 字符设备
- 以字符为基本单位,发送 | 接收 字符流数据,不可寻址 & 无法寻道
- 例如:鼠标、打印机
2) 设备控制器
- 是什么?
- 控制 一个 | 多个 IO 设备,并有自己的寄存器,可以实现 IO 设备 和 计算机之间的数据交换
- 当控制 一个 设备时,只有一个设备地址
- 当控制 多个 设备时,含有多个设备地址,且每个设备对应一个地址
- 属于硬件范畴
- 可以和操作系统的 CPU 进行通信,接收 CPU 指令信息,并对自己负责的设备进行相关控制
- 控制 一个 | 多个 IO 设备,并有自己的寄存器,可以实现 IO 设备 和 计算机之间的数据交换
- 作用
- 接收 & 识别命令
- 接收来自 CPU 的指令,并识别;内部有寄存器,可以存放指令 & 参数
- 进行数据交换
- 向上与 CPU 进行数据交换
- 向下与 硬件设备 进行数据交换
- 地址识别
- 识别不同地址对应哪个硬件设备
- 差错检测
- 对硬件设备传过来的数据进行检测
- 接收 & 识别命令
- 分类:
- 字符设备控制器
- 块设备控制器
- 如何通信?
- 通过读取设备控制器的寄存器中的相关值,可以得知设备的状态,例如是否可以接收新指令等
- 通过向设备寄存器中写入一些指令,可以对设备进程相关控制
- 寄存器的种类?
- 状态寄存器
- 标识寄存器的状态, 例如
- 工作状态
- CPU 此时发送指令 | 数据均无效
- 工作完成状态
- CPU 发送的指令 | 数据能够被设备寄存器接收
- 工作状态
- 标识寄存器的状态, 例如
- 命令寄存器
- CPU 发送命令通知 IO 设备进行输入 | 输出操作
- 设备控制器控制设备进行相关操作
- 操作完成后,会修改 状态寄存器 的状态为 工作完成状态
- 数据寄存器
- CPU 向硬件设备写入传输数据时,CPU 需要发送一个个字符数据给设备
- 这些数据存储在数据寄存器中
- 状态寄存器
3) 驱动程序
- 是什么?
- 操作系统的一部分
- 属于软件范畴
- 运行位置:
- 通常为操作系统内核的一部分,
- 但也可以构造用户空间的设备驱动程序,这样避免了有问题的驱动程序干扰内核,造成内核的崩溃,但大多数桌面系统要求驱动程序必须运行在内核中
- 驱动程序如何装入操作系统?
- 将内核与设备驱动程序重新连接,然后重启系统 -
Unix系统采用该方式 - 在操作系统文件中设置一个入口,通知该文件需要一个设备驱动程序,然后重启系统,在重启系统时,操作系统寻找有关的设备驱动程序并装载进内核 -
Windows系统采用 - 操作系统在运行时接收新的设备驱动程序并立即安装,而无需重启系统 -
热插拔设备,例 USB 等
- 将内核与设备驱动程序重新连接,然后重启系统 -
- 作用
- 由于设备控制器间的寄存器、缓冲区等的不同,为了屏蔽设备控制器间的差异
- 设备控制器会提供统一接口给操作系统
- 操作系统通过驱动程序使用统一 API 与不同的设备控制器进行通信
- 存放设备的中断处理函数,当发生中断时,会被调用
- IO 中断流程:
2. IO 控制方式
- 当 CPU 发送指令给设备控制器,从而读写数据,设备读完成功后,如何将该信息通知给 CPU
- 这个实现方式,就是 IO 控制方式
- 主要有以下几种方式:
1) 轮询
- 设备控制器中有个寄存器,是 状态寄存器,它记录了设备当前工作是否完成的状态
- CPU 通过不断 轮询 该状态寄存器,读取设备当前状态,来获取设备是否已经完成
- 特点:
- 占用 CPU 资源,CPU 无法做其他事情,效率低

2) 中断
- 外部设备中,一般都含有 中断控制器,当数据处理完毕后,中断控制器会发送中断信号给 CPU,
- CPU 此时就保护现场 -> 设备驱动程序执行内在的中断处理函数 -> 恢复现场,可参见 上一节的 IO 中断流程
- 这里的中断处理函数中,CPU 主要工作是将 数据从 磁盘缓冲区 复制到 内核缓冲区,再从内核缓冲区 复制到 用户缓冲区
- 这属于 硬件中断
- 特点:
- 在中断信号到来前,CPU 可以处理其他事务,效率比轮询高
- 若是频繁读写数据,那么 中断信号 也频繁,会经常打断 CPU 的执行,保护现场 & 恢复现场 需要花费时间,会降低 CPU 的效率
3) DMA
- 外部设备发起 中断请求,通知 DMA 控制器,由 DMA 控制器 负责将 磁盘缓冲区的数据 复制到 内核缓冲区
- 复制完成后,通知 CPU,此过程中,CPU 将数据 从 内核缓冲区 复制到 用户缓冲区
- 特点:
- CPU 减少一次数据的复制,可以有更多的时间处理其他事务,效率进一步提高
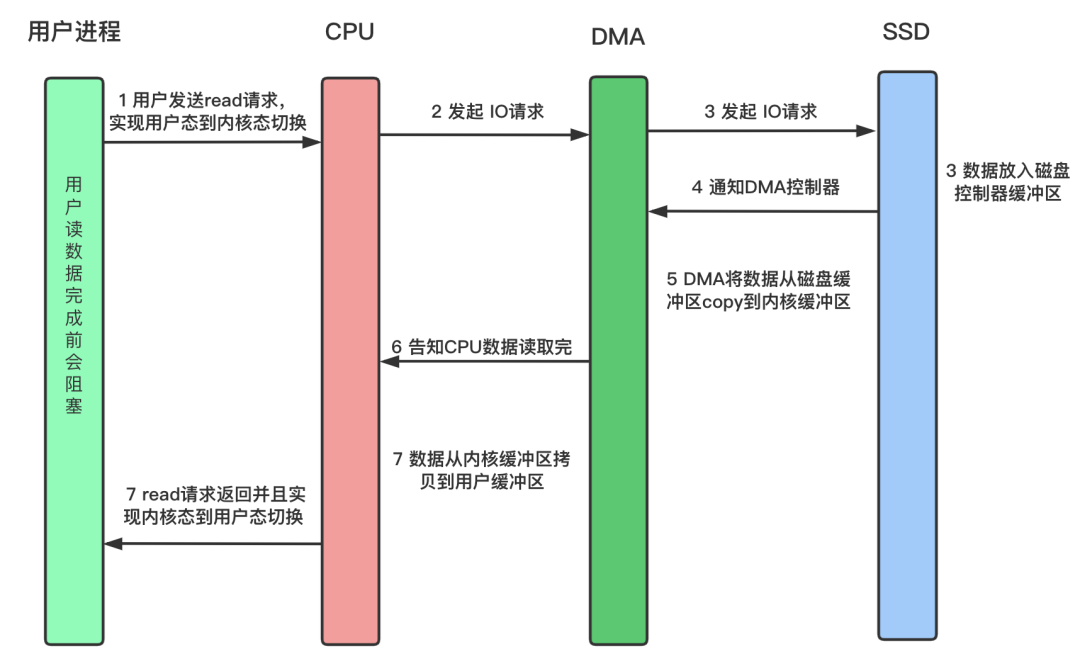
- 具体流程:
- CPU 对 DMA 控制器进行发送指令,表示自己想读取哪些数据,以及数据读取后放在 内核缓冲区 的哪个位置
- DMA 控制器 与设备控制器进行交互,发送相关指令,通知外部设备将数据复制到 磁盘缓冲区,复制完成后,通过 DMA 控制器
- DMA 控制器 接收到成功信息后,负责将 数据从 磁盘缓冲区 -> 内核缓冲区,完成后,产生中断信号,通知 CPU
- CPU 接收到成功信号后,将 数据从 内核缓冲区 -> 用户缓冲区,再由内核态切换回用户态
3. IO 分类
4. IO 分层
1) 通用块层
- 作用
- 向上为 文件系统 & 应用程序 提供访问块设备的标准接口;向下将不同的磁盘设备抽象为统一的块设备,在内核层面,负责管理 & 存储磁盘数据
- 为 文件系统 & 应用程序 发来的 IO 请求排队,对队列重排序、合并多个 IO 请求 等,提高磁盘读写效率
2) IO 调度算法
没有调度算法
- 内核 不为 IO 做任何处理
- 常用于 虚拟机 IO,完全交由物理机系统负责
FIFO
时间片轮转
- 内核 为每个 进程 维护一个 IO 调度队列,进程中的每个 IO 分配相同时间片
- 默认 IO 调度算法
基于优先级
- 优先级高的 IO 请求先行发生
- 适用于 大量进程的系统,例如 桌面环境
最终期限调度
- 分别为 读、写 请求创建不同的 IO 队列,确保达到最终期限的请求先行处理
- 适用于 IO 压力比较大的场景,例如 数据库
5. 磁盘调度算法
1) FIFO
- 先来先服务
- 特点:
- 简单粗暴
- 若大量进程竞争使用磁盘,由于在不同磁道上,性能下降
2) 最短寻道时间优先
- 优先选择从当前磁头位置到 所有请求磁道位置 中的最近的 磁道
- 特点:
- 导致某些磁道一直得不到寻道,产生饥饿现象
3) 扫描算法
- 磁头从一端到另一端移动,遇到请求磁道位置,处理该磁道请求,然后继续移动,直到这个方向上没有了更大的磁道请求,然后调转方向,处理另一端
- 这个 端 并非指当前所有请求的端点,而是实际磁道的 端点,因此 端点是固定的
- 特点:
- 解决饥饿问题
- 中间磁道请求比两侧请求等待的时间要短,
- 例如,当前为中点位置,中点位置刚过,中点处就有新的请求,右端点也有请求
- 到达右端点请求需要等待半个磁道的时间,然后调转,刚调转,右端点又有新的请求
- 到达中点位置,上一个在中点处等待的请求等待了 1 个磁道的时间,刚走,中点又有新的请求
- 这个中点的新请求需要等待 1 个磁道的时间被处理
- 右端点的新请求等待 2 个磁道的时间被处理
- 可以看出,端点处一般需要等待 2 个磁道的时间,需要从 右端点 到 左端点,再从 左端点 到 右端点
- 而中点处一般需要等待 1 个磁道的时间,需要从 中点 到 任意一个端点,再从 端点 到中点
4) 循环扫描算法
- 磁头总是从一端向另一端移动,同时处理该方向上的磁道请求,当移到边界时,快速返回到起始端,这次不处理任何请求
- 这个 端 并非指当前所有请求的端点,而是实际磁道的 端点,因此 端点是固定的
- 特点:
- 解决因磁道位置不同,而等待的时间差异,可保证所有位置请求等待时间几乎相同
5) Look & C-Look 算法
- Look
- 和 扫描算法 类似,区别在于 这个 端 是指当前所有请求的端点,因此 端点是变动的
- C-Look
- 和 循环扫描算法 类似,区别在于 这个 端 是指当前所有请求的端点,因此 端点是变动的
6. 零拷贝
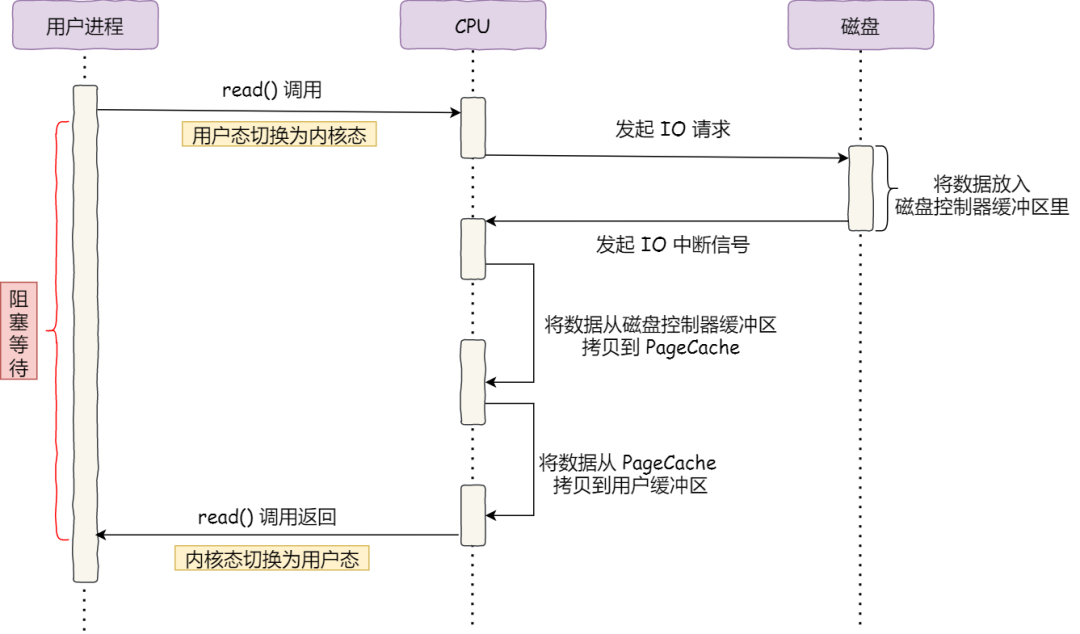
1) 不用 DMA
- 不使用 DMA 传输数据之前,IO 过程如下所示:
- 特点:
- CPU 需要参与 磁盘缓冲区 -> 内核缓冲区 + 内核缓冲区 -> 用户缓冲区 2 个复制过程
- CPU 负责数据的复制工作,无法处理多余的事情,性能较差
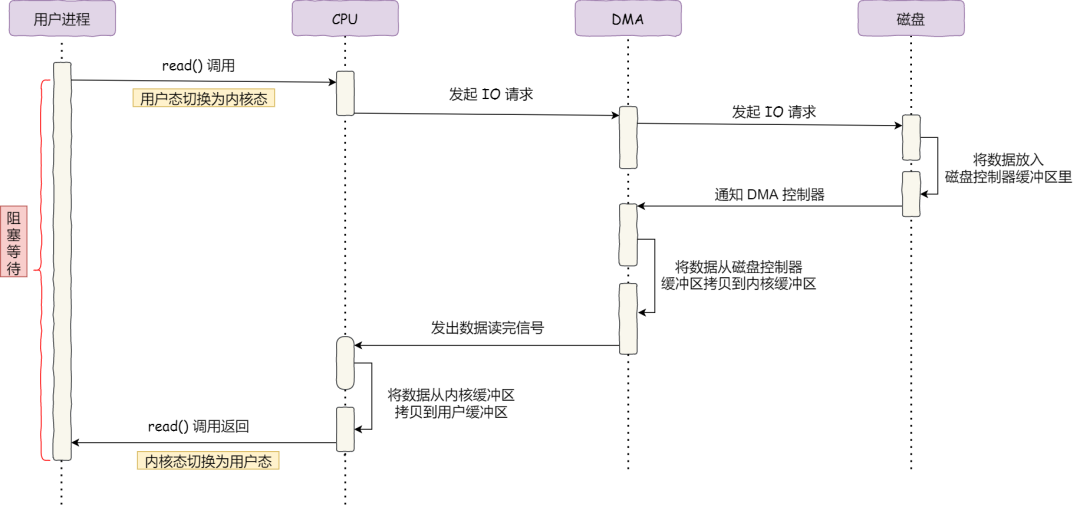
2) 借助 DMA 控制器
- 使用 DMA 控制器后,IO 过程如下所示:
- 特点:
- CPU 不参与数据的复制工作,可以有多余的空间进行其他事务,性能提高
- 文件传输过程:
- 2 个系统调用指令
read(file, tmp_buf, len);&&write(socket, tmp_buf, len); - 2 大次 [4 小次] 用户态 & 内核态 的切换过程 + 2 次 DMA 数据拷贝 + 2 次 CPU 数据拷贝
read&write各需要发生系统调用,从 用户态 -> 内核态 + 内核态 -> 用户态- DMA: 磁盘缓冲区 --> 内核缓冲区 + 内核缓冲区 --> 网卡缓冲区
- CPU: 内核缓冲区 --> 用户缓冲区 + 用户缓冲区 --> socket 缓冲区
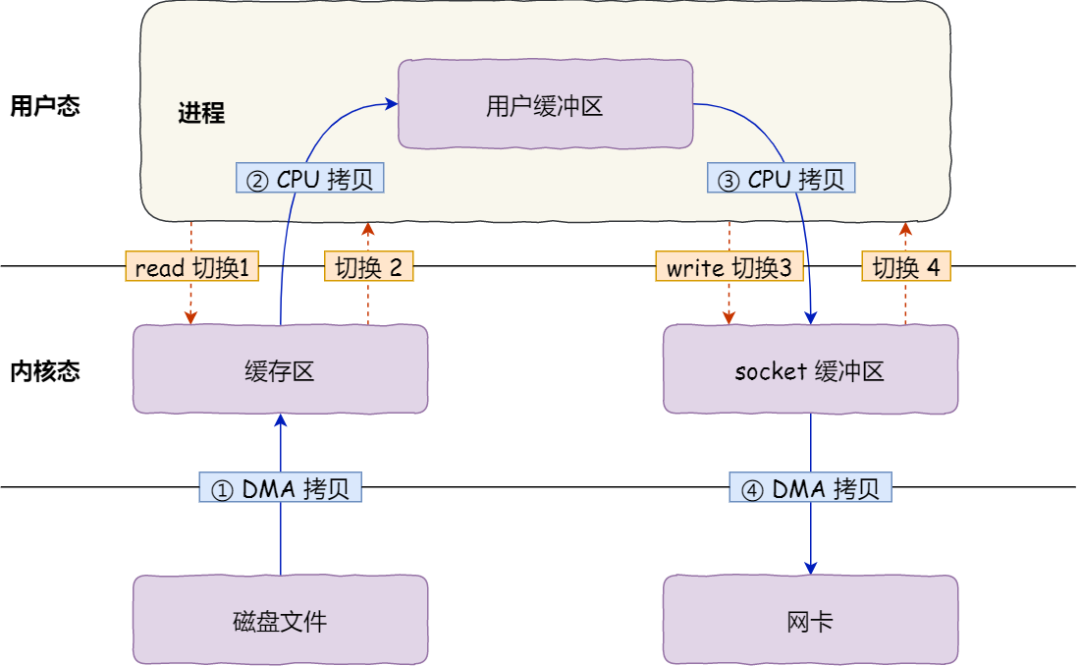
- 2 个系统调用指令
3) mmap & write
- 文件传输过程:
- 2 个系统调用指令
buf = mmap(file, len);&&write(sockfd, buf, len); - 2 大次 [4 小次] 用户态 & 内核态 的切换过程 + 2 次 DMA 数据拷贝 + 1 次 CPU 数据拷贝
mmap&write各需要发生系统调用,从 用户态 -> 内核态 + 内核态 -> 用户态- DMA: 磁盘缓冲区 --> 内核缓冲区 + 内核缓冲区 --> 网卡缓冲区
- CPU: 由于内核缓冲区 & 用户缓冲区共享,因此,只需要在
write时, 内核缓冲区 --> socket 缓冲区
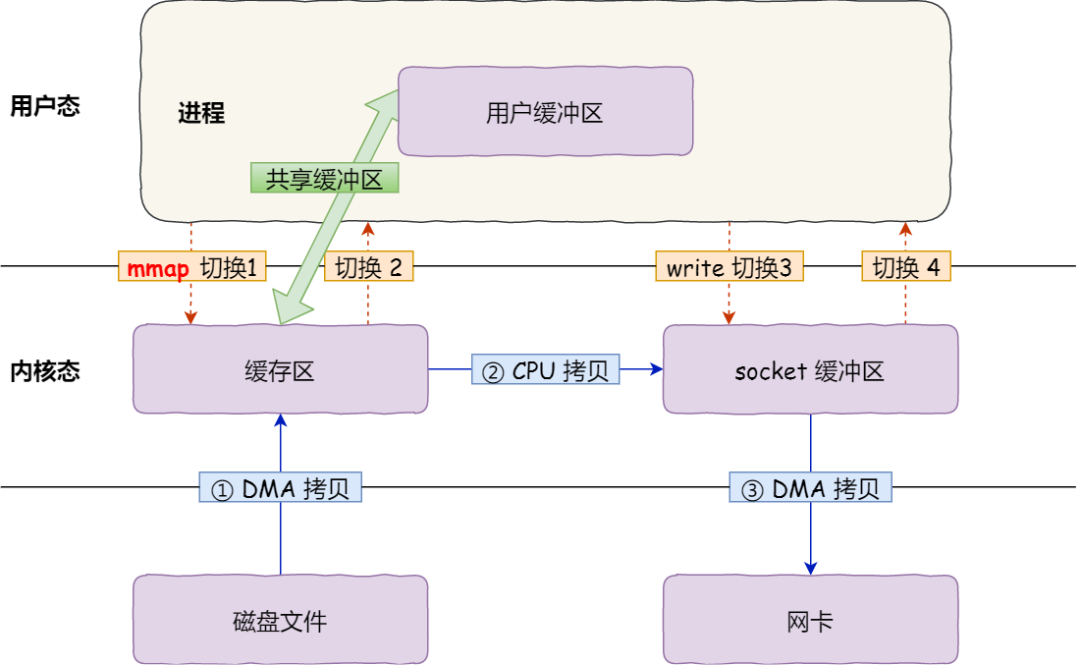
- 2 个系统调用指令
- mmap 的原理:
- 发起 系统调用,将 磁盘文件的内容 映射到 堆外的直接内存 中,跳过 内核缓冲区,因此也不需要 内核缓冲区 --> 用户缓冲区 的数据复制过程
- 返回 直接内存是 虚拟内存,意味着 byteBuffer 中的内容不一定都在 物理内存 中
- 要让这些内容加载到物理内存,可以调用 MappedByteBuffer.load()
- 对于大多数操作系统来说,将 文件映射到内存 这个操作本身 开销较大
- 如果操作的文件很小,只有数十KB,映射文件所获得的好处将不及其开销
- 因此,只有在操作 大文件 的时候才将其映射到 直接内存
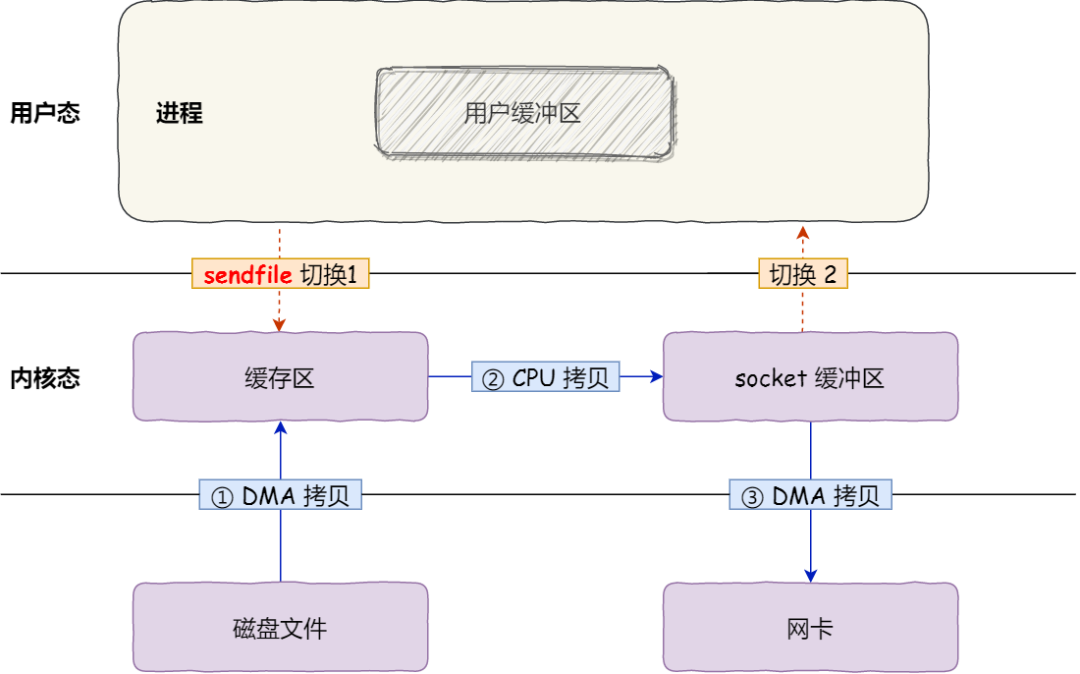
4) sendfile
- 1 个 系统调用函数 [
Linux 2.1开始提供]
// out_fd : 目的文件描述符
// in_fd: 源文件描述符
// offset: 源文件内偏移量
// count: 打算复制数据长度
// ssize_t: 实际上复制数据的长度
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
- 对应 Java NIO 库中的
transferTo函数
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
- 1 大次 [2 小次] 用户态 & 内核态 的切换过程 + 2 次 DMA 数据拷贝 + 1 次 CPU 数据拷贝
sendfile发生一次系统调用
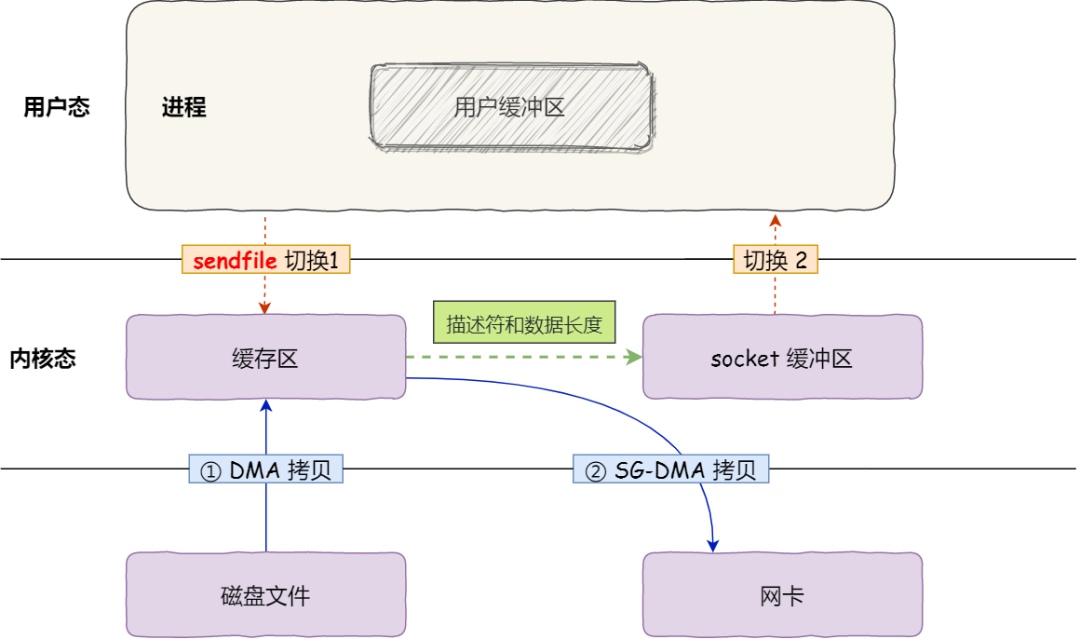
5) SG-DMA
- 查看网卡是否支持 SC-DMA 技术 [
Linux 2.4开始支持]
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on
- 1 个 系统调用函数
// out_fd : 目的文件描述符
// in_fd: 源文件描述符
// offset: 源文件内偏移量
// count: 打算复制数据长度
// ssize_t: 实际上复制数据的长度
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
- 1 大次 [2 小次] 用户态 & 内核态 的切换过程 + 1 次 DMA 数据拷贝 + 1 次 SG-DMA 数据拷贝
- DMA: 磁盘缓冲区 --> 内核缓冲区
- SG-DMA: 内核缓冲区 --> 网卡缓冲区 在此之前,CPU 将 内核缓冲区的描述符 & 数据长度 传到 socket 缓冲区
5) 零拷贝分析
- 适用场景:
- 小文件的拷贝过程
- 大文件的拷贝采用 异步 IO,直接将数据从 磁盘缓冲区 复制到 用户缓冲区,不经过 内核缓冲区,不经过 内核缓冲区 的 IO 也称为 直接 IO
- 原因:
- 数据从 磁盘缓冲区 复制到 内核缓冲区,这个内核缓冲区实际就是
PageCache,即 磁盘高速缓存 PageCache大小有限,最好是存放多个小的热点数据,而大文件会导致 PageCache 中热点数据被覆盖,PageCache 效果大大折扣
- 数据从 磁盘缓冲区 复制到 内核缓冲区,这个内核缓冲区实际就是
- 应用场景:
KafkaNginx