ZooKeeper
2022年10月10日
- 中间件
ZooKeeper
1. 概述
1) 作用
- 为分布式系统提供协调服务
- 服务命名
- 通过 顺序节点 生成全局唯一 id
- 服务注册 & 订阅
- 服务端将自己注册到 ZK 假设 '/server' 节点下
- 客户端订阅 '/server' 节点,获取有哪些服务端可以提供服务
- 分布式通知
- 通过 监听 想要的节点,进行后续处理
- 或改变 某节点状态,让其他需要该节点数据的其他服务收到通知
- 分布式锁
2) 应用场景
- Kafka
2. 相关概念
1) 节点
- ZooKeeper 为 树状目录结构,每个节点称为
znode,以 '/' 分割表示层级 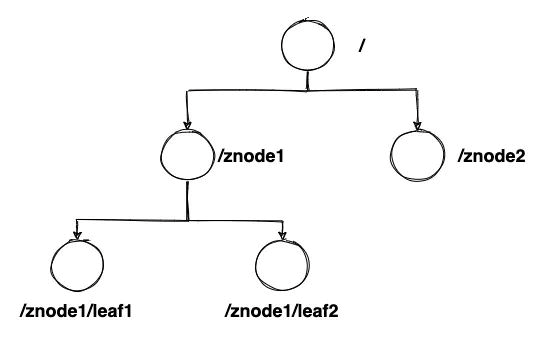
① 四种类型
// -s 顺序节点,节点名称后面自动递增添加数字后缀
// -e 临时节点
create [-s][-e] path data acl
- 持久节点[Persistent]
- 客户端与 ZK 服务器端断开连接后,该节点仍然存在,不会被删除
create /liuxian "tunfo"根目录下创建一个liuxian的节点,数据值为tunfo
- 临时节点[Ephemeral]
- 客户端与 ZK 服务器端断开连接后,该节点会被删除
- 只能作为叶子节点
/create -e /zhishou "fengchan"根目录下创建一个zhishou的节点,数据值为fengchan
- 持久顺序节点[Persistent_sequential]
- 除了具备持久性外,在注册时,节点名称保证同一父节点下的顺序性
create -s /ps 11根目录下创建一个ps0000000001的节点,数据值为11
- 临时顺序节点[Ephemeral_sequential]
- 除了具备临时性外,在注册时,节点名称保证同节点下的顺序性
create -e -s /es 11根目录下创建一个es0000000001的节点,数据值为11
② 数据结构
stat- 保存状态信息
- 状态信息有以下内容:
cZxid- 创建时的事务 id
ctime- 创建时间,从 1970 年开始
mZxid- 最后一次修改时的事务 id
mtime- 最后一次修改时间
numChildren- 子节点个数
pZxid- 子节点 最后一次修改时的事务 id
cversion- 子节点版本号,表示修改次数
dataVersion- 当前节点数据版本号,表示修改次数
aclVersion- 当前节点的
ACL[权限控制] 版本号
- 当前节点的
ephemeralOwner- 若是持久节点 == 0
- 若为临时节点 == 创建该临时节点的会话 id
dataLength- 数据长度
data- 保存实际存放的数据内容
③ 操作权限
create- 可以创建子节点
delete- 可以删除子节点
read- 可以获取该节点数据及其子节点信息
write- 可以修改节点数据
admin- 可以设置该节点的 ACL 权限
④ 节点监听
- 流程
- 客户端可以在任意节点向服务端注册 事件监听器 [
Watcher] 监听该节点, 客户端保存该 Watcher 对象到本地的WatcherManager中 - 当服务端该节点有事件发生时,ZooKeeper 服务端会将事件通知到对此感兴趣的客户端处
- 监听节点的
数据发生改变 - 监听节点的
子节点数发生改变
- 监听节点的
- 客户端收到该通知后,从
WatcherManager中取出该Watcher对象执行回调逻辑
- 客户端可以在任意节点向服务端注册 事件监听器 [
- 特点
- 一次性
- 一个 Watcher 对象被触发后,客户端取出该 Watcher 对象后,本地存储将不再有该 Watcher 对象
- 客户端串行
- 客户端接收到的 Watcher 后执行回调是串行的,若一个回调逻辑阻塞,后续 Watcher 的回调也会被阻塞
- 轻量
- 服务端只会通知 状态、事件类型、节点路径,不包含具体事件内容,若需要则客户端需要主动去服务端获取
- 一次性
2) 身份认证方式
worlddefault- 所有用户均可访问
auth- 只有已认证用户可访问
digest- 用户名 : 密码 方式
ip- 对 ip 进行指定
3) 会话
- ZooKeeper 服务端与 一个 ZooKeeper 客户端建立的 一次 长连接,就是一个会话
- 每个会话有唯一 会话 id
- 客户端 & 服务器端 通过
心跳检测机制保证双方在线 - TCP - 若某时刻某个客户端断线,在 SessionTimeout 范围内,该客户端仍未与 集群中的任一服务器建立连接,则该会话失效
3. 集群
1) 主要角色
- ZooKeeper 一般以 集群 的形式搭建,主要由以下几种不同角色
① Leader
- 节点的
写入、读取、参与 Leader 选举、负责数据同步
② Follower
- 节点的
读取、参与 Leader 选举
③ Observer
- 节点的
读取 - 防止太多从节点参与选举 & 过半写判断,影响性能;便于横向扩展,只需要增加 Observer 即可
2) Leader 选举
① 选举标准
zxidlong型 64 位整数,分为 2 部分:- 纪元
epoch- 每次选举 epoch 改变
- 计数器
counter
- 纪元
server id
/*
* We return true if one of the following three cases hold:
* 1- New epoch is higher 选 epoch 更大的
* 2- New epoch is the same as current epoch, but new zxid is higher 选 zxid 更大的
* 3- New epoch is the same as current epoch, new zxid is the same
* as current zxid, but server id is higher. 选 server id 更大的,代表配置更好的机器
*/
return ((newEpoch > curEpoch)
|| ((newEpoch == curEpoch)
&& ((newZxid > curZxid)
|| ((newZxid == curZxid)
&& (newId > curId)))));
② 选举过程中节点状态
LeadingLookingFollowing
③ 选举流程
- 服务启动时的选举
- 每个节点选举自己成为 Leader,并将投票信息广播方式传给集群中的其他节点
- 节点收到其他节点的投票信息后,与自己的投票情况比较,此时节点处于
Looking状态- 优先选择 zxid 大的投票结果
- zxid 相同时,选择 myid 大的投票结果
- 若需要修改自己的投票情况,则再次广播该信息
- 若集群中过半的机器均选择了某个节点作为 Leader,选举结束
- 更新节点状态,Leader 为
Leading状态,Follower 为Following状态 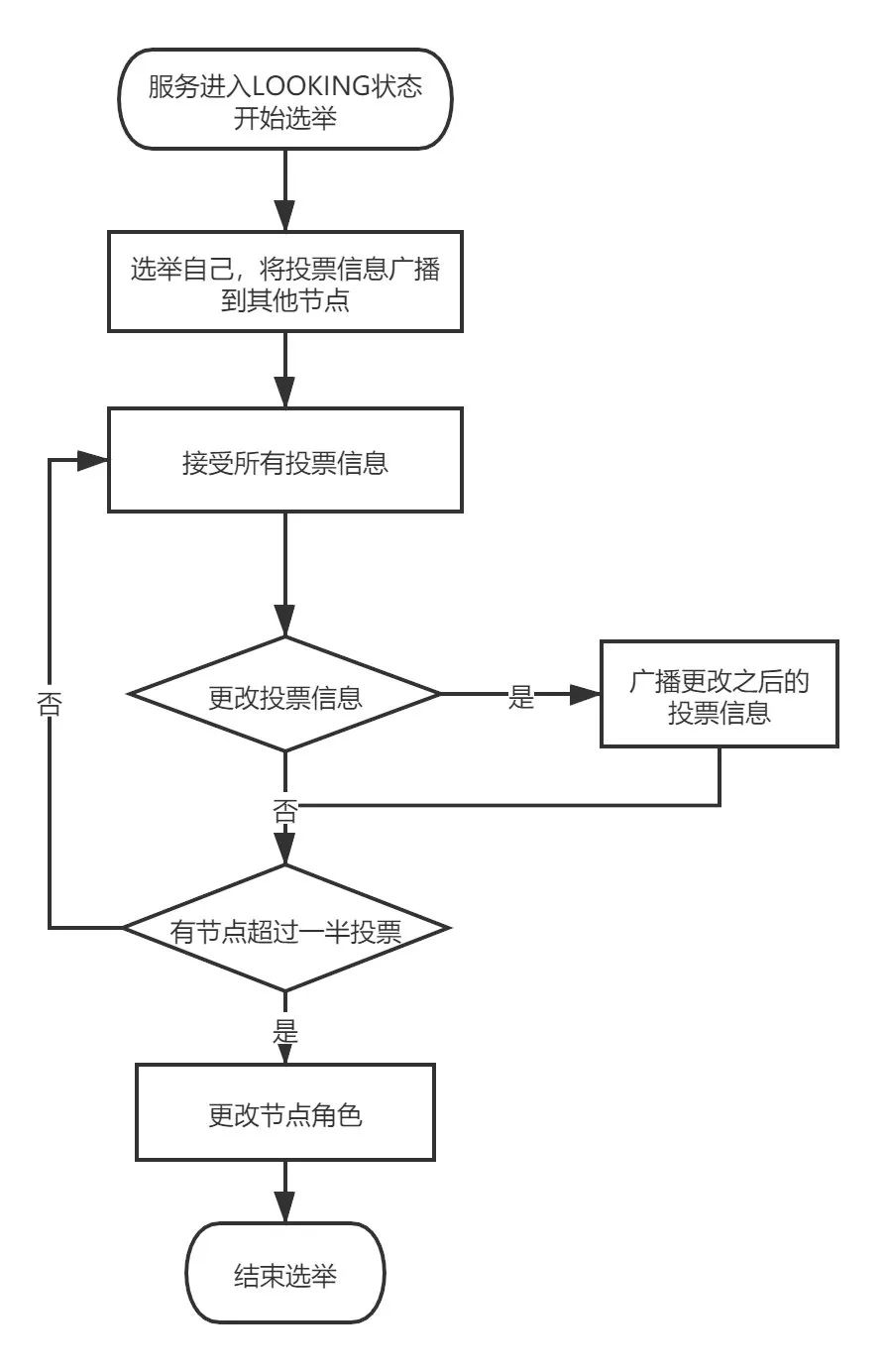
- 服务运行期间的选举
- 若 Leader 节点宕机,则 Follower 节点会修改自身状态为
Looking,重新进入选举流程 - 生成投票信息 [myid, zxid],第一轮仍然都投自己,将投票信息比较后,再次广播
- 直到过半机器选择某个节点,更新节点状态
- 若 Leader 节点宕机,则 Follower 节点会修改自身状态为
3) 选举后的数据同步
- 选举完成后,Follower & Observer [统称 Learner] 会向 Leader 注册,然后开始数据同步的过程
① 同步标准
PeerLastZxidLearner服务器最后处理的zxid
minCommittedLogLeader提议缓存队列中的min zxid
maxCommittedLogLeader提议缓存队列中的max zxid
② 同步方式
- 直接差异化同步
- 前提:
PeerLastZxid∈ [minCommittedLog,maxCommittedLog)
- 流程:
- Leader 向 Learner 发送 diff 指令,表示开始进行差异化同步
- Leader 将 (
PeerLastZxid,maxCommittedLog] 数据作为 proposal 发送给 Learner - Leader 发送 NEWLEADER 命令给 Learner,表示本节点为选举出来的 Leader,Learner 同步完成后返回 ACK 应答
- 过半 Learner 响应 ACK 后,Leader 发送 upToDate 命令给 Learner,表示 更新完成,Learner 收到后返回 ACK
- 前提:
- 先回滚再差异化同步
- 前提:
PeerLastZxid∈ [minCommittedLog,maxCommittedLog) 但不存在于 新 Leader 中
- 流程:
- 将不存在于 新 Leader 的事务回滚,再进行差异化同步
- 前提:
- 仅回滚同步
- 前提:
PeerLastZxid>maxCommittedLog
- 流程:
- 将不存在于 新 Leader 的事务回滚
- 前提:
- 全量同步
- 前提:
PeerLastZxid<minCommittedLog- Leader 上没有提议缓存队列 &&
PeerLastZxid!= Leader のmax zxid
- 流程:
- Leader 发送 SNAP 命令,将全部数据同步到 Learner
- 前提:
4. 数据一致性问题
- ZooKeeper 遵循的 CP 一致性协议,保证 分区容忍性 & 数据一致性
1) ZK 如何保证 数据一致性?
- 借助 ZAB 原子广播协议 实现,该方式分为 两阶段,但不等同于 2PC
2) ZK 什么情况下会出现 数据不一致 的情况?
- 查询不一致
- 过半写只能保证过半写成功的节点数据与 Leader 一致,其他的要等到数据同步才可一致
5. ZAB
1) ZAB 状态
public enum ZabState {
ELECTION, // 选举
DISCOVERY, // 选举后 Learner 与 Leader 建立连接
SYNCHRONIZATION, // 与 Leader 进行数据同步
BROADCAST // 消息广播,可以对外提供服务
}
2) 消息广播
- ZK 中只有 Leader 可以写入数据,因此其他节点接收到写入请求时,转发给 Leader 进行处理
① 流程
Leader收到写入请求后,生成一个proposal提议,每个proposal提议拥有一个全局唯一递增的事务 id[zxid]Leader将提议放入一个FIFO队列中,按照 FIFO 顺序发送给所有FollowerFollower收到提议后,以 事务日志 的形式写入本地磁盘,写入成功后回复ACKLeader收到 过半ACK后认为可以写入数据,发送Commit命令给Follower通知可以提交该proposal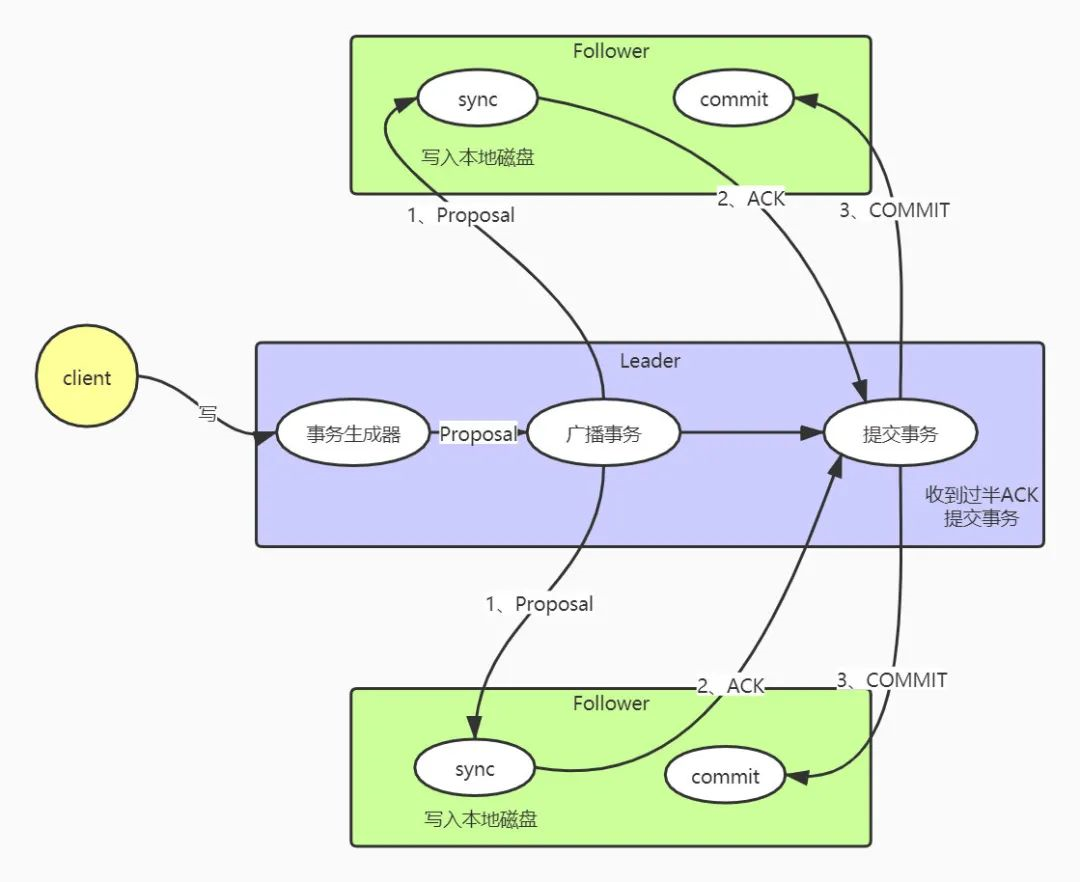
6. ZK 分布式锁
1) 如何实现?
- 每个服务在某个节点下均创建 临时有序节点
- 获取该节点下的 所有子节点 列表,对其进行排序,并判断自己所创建的节点是否为最小的节点
- 如果是,说明获得锁,可以继续执行;执行完成 | 客户端断线后,该临时有序节点自动删除
- 如果不是,监听自己前一个比它小的节点,判断是否存在,如果不存在,说明自己可以获得锁,进行后续操作
2) 优点
- 可靠性高,实现简单
3) 缺点
- 性能没有 缓存 高
- 频繁创建、删除 节点性能受到影响,只能由 Leader 进行操作,然后同步到所有的 Follower 中
7. 补充
1) ZK 服务器为什么推荐为 奇数?
- 假设有 奇数 n,过半 == n / 2 + 1
- 偶数 x 要想达到过半效果,则过半 == x / 2 + 1
- n / 2 + 1 == x / 2 + 1 --> x == n + 1
- 即,要达到同样的过半效果,奇数比偶数 小 1 台,节约了开销
2) 过半机制如何防止脑裂?
- 脑裂
- 某个时刻集群因为网络等原因,分为了一个个小团体,每个小团体选出了各自的 Leader
- 当恢复为一个团体时,出现了多个 Leader 同时存在的情况
- 过半机制防止脑裂
- 分成小团体后,过半机制保证最多只能有一个小团体可以达到半数以上,从而成功选举出 Leader,其他小团体即使全部同意也达不到过半的硬性要求