🌕🌕 187. 重复的DNA序列
2022年10月10日
- algorithm
🌕🌕 187. 重复的DNA序列
难度:🌕🌕
问题描述
解法 1
class Solution {
public List<String> findRepeatedDnaSequences(String s) {
// 思路:
// 借助 HashMap
// method 1
int len = s.length();
List<String> res = new ArrayList<>();
if(len <= 10) {
return res;
}
// len > 10
HashMap<String, Integer> map = new HashMap<>();
for(int i = 0; i < len - 10 + 1; i ++) {
String cur = s.substring(i, i + 10);
if(!map.containsKey(cur)) {
map.put(cur, 1);
} else {
int fre = map.get(cur);
fre ++;
map.put(cur, fre);
if(fre == 2) {
res.add(cur);
}
}
}
return res;
}
}
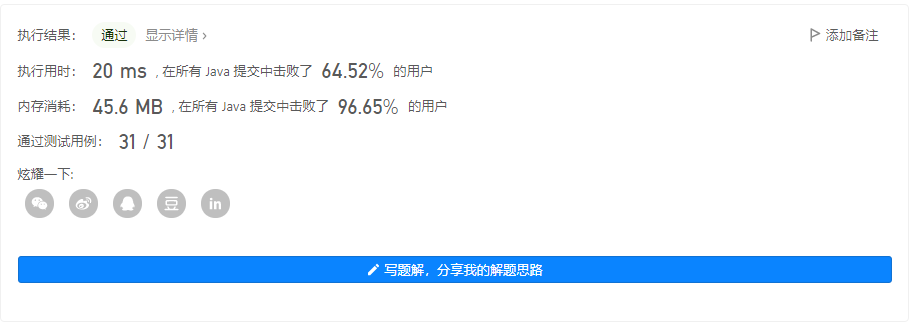
输出 1
解法 2 - 优化
class Solution {
public List<String> findRepeatedDnaSequences(String s) {
// 思路:
// 借助 HashMap
// method 2
// 由于核苷酸只有 4 种,且每种都是一个字符表示,因此可以用 位 来表示这 4 种核苷酸
// A - 00 ; C - 01 ; G - 10 ; T - 11
// 那么 长度 = 10 的子串就可以转换为 长度 = 10 的 0 & 1 组成的 int 数
// 若即使如此,没有优化,复杂度依然不会降低,可以借助 位运算 快速得到 长度 20 的 int 值
// 维护一个滑动窗口,长度 20,首次的值需要计算
// 之后的窗口每次滑动,需要去除 首 2 位,然后 左移 2 位,再加上新值代表的 2 位 2进制数
int len = s.length();
List<String> res = new ArrayList<>();
if(len <= 10) {
return res;
}
// len > 10
HashMap<Integer, Integer> map = new HashMap<>();
HashMap<Character, Integer> dict = new HashMap<>();
dict.put('A', 0);
dict.put('C', 1);
dict.put('G', 2);
dict.put('T', 3);
int cur = 0;
// 获取首个窗口代表的 int 值
for(int i = 0; i < 10; i ++) {
cur <<= 2;
cur |= dict.get(s.charAt(i));
}
map.put(cur, 1);
System.out.println(cur);
for(int i = 1; i <= len - 10; i ++) {
cur <<= 2; // 左移 2 位,去除高位影响,高位对应着前面的字符
cur |= dict.get(s.charAt(i + 10 -1));
// 假设 cur 为 20位,左移 2 位后,变为 22 位,但实际上应该只取后 20 位的数,所以需要将高 12 位屏蔽
// 1 << 20 - 1 这样高位全部为 1,只有低 20 位 == 1,相与,可以得到只有剩余 20 位的值
cur &= ((1 << 20) - 1);
// System.out.println(cur);
if(!map.containsKey(cur)) {
map.put(cur, 1);
} else {
int fre = map.get(cur);
fre ++;
map.put(cur, fre);
if(fre == 2) {
res.add(s.substring(i, i + 10));
}
}
}
return res;
}
}
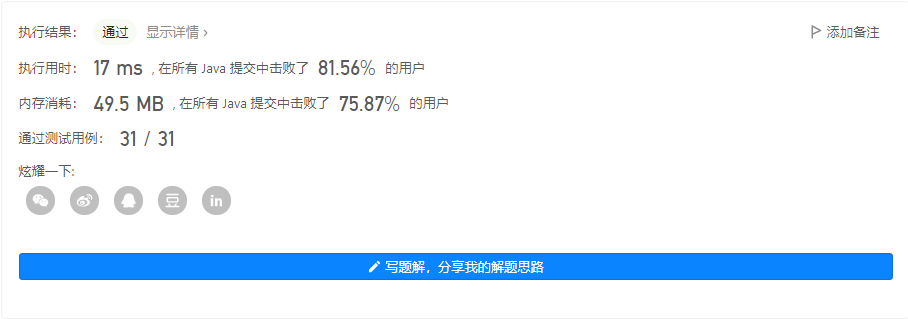
输出 2