🍖 Dubbo
2022年10月10日
- 框架
🍖 Dubbo
1. 总体架构
1) 结构图
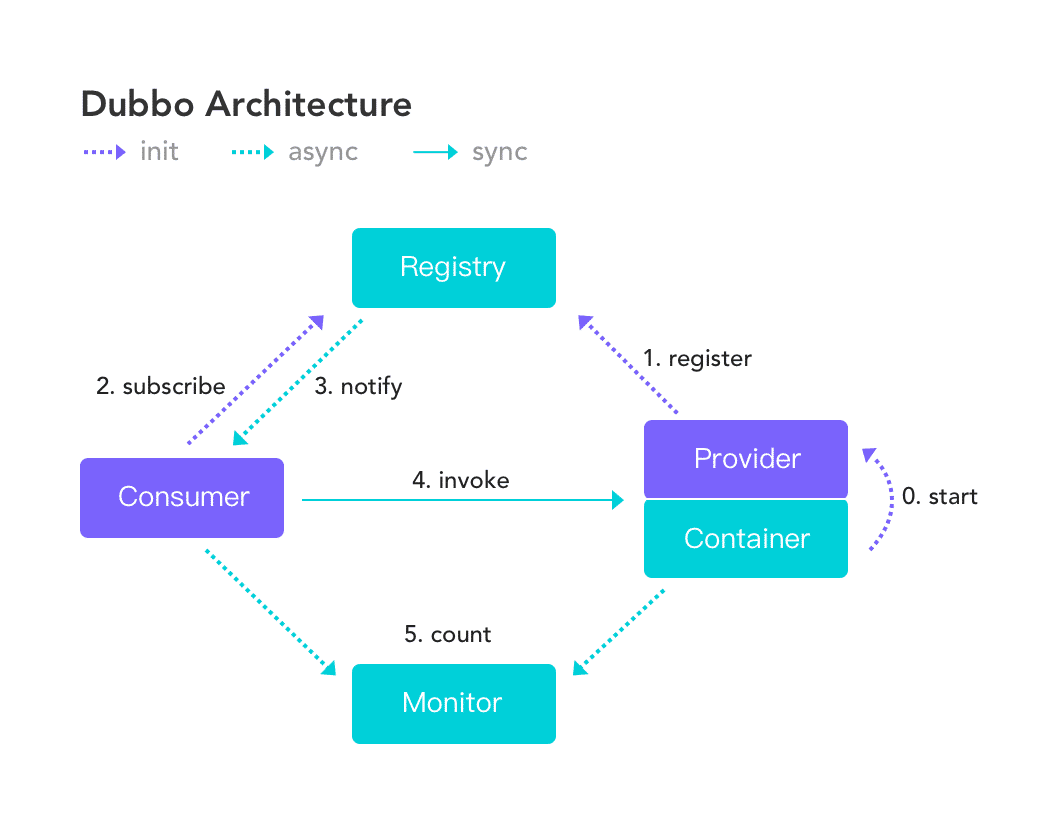
2) 节点说明
| 节点 | 描述 |
|---|---|
Provider | 暴露服务的 服务提供者 |
Consumer | 远程调用服务的 服务消费者 |
Registry | 服务注册 & 发现的 注册中心 |
Monitor | 统计 服务调用次数 & 调用时间 的 监控中心 |
Container | 服务运行容器 |
3) 流程说明
Container负责启动,加载,运行ProviderProvider在启动时,向Registry注册自己提供的服务Consumer在启动时,向Registry订阅自己所需的服务Registry返回Provider地址列表 给Consumer- 如果有变更,
Registry将基于 长连接 推送变更数据给Consumer
- 如果有变更,
Consumer从Provider地址列表 中,基于 软负载均衡 算法,选一台Provider进行调用- 如果调用失败,再选另一台调用
Provider&Consumer在内存中累计 调用次数 和 调用时间,定时 每分钟发送一次统计数据到Monitor
2. 分层
- Business
service业务逻辑层- 提供 接口 & 实现
- RPC
config配置层- 初始化 配置信息,注意围绕 ServiceConfig & ReferenceConfig
proxy代理层- Provider & Consumer 都会生成代理类,使得 服务接口透明化
- 提供远程调用 & 返回结果
registry注册中心层- 提供 服务地址的注册与发现
cluster路由层- 提供 负载均衡 & 远程调用失败的容错措施
monitor监控层- 记录 RPC 调用次数 & 调用时间
protocol远程调用层- 封装 RPC 调用,主要负载管理 Invoker
exchange信息交换层- 封装请求响应模式,同步转异步
- Remoting
transport网络传输层- 抽象网络传输的 统一接口
- 提供 Netty & Mina 两种传输模式
serialize数据序列化层- 对 需要在网络传输的数据 进行序列化 & 反序列化
微内核 & SPI 机制
SPI
- JDK 内置的一个 服务发现机制
- 程序运行过程中会读取 配置文件,通过 反射 加载实现类,当修改配置文件时,就会 动态替换接口的实现类
- 使得 接口 & 具体实现 完全解耦,只需要声明 接口,具体实现可以在 配置 中选择
- 在
META-INF/dubbo/目录下放置一个与 接口 同名的 文本文件,文本的内容为 接口的实现类的全限定名,多个实现类用 换行符 分隔 - 例:
- 实现了 Dubbo 的负载均衡类,具体实现类为
MyLoadBalance implements LoadBalance - 在
META-INF/dubbo/目录下添加 文件org.apache.dubbo.rpc.cluster.LoadBalance - 文本内容为
xxx=com.example.MyLoadBalance
- 实现了 Dubbo 的负载均衡类,具体实现类为
- 在
Dubbo 自己实现了 SPI 机制
- Java 的 SPI 在查找扩展实现类时,会遍历 SPI 的配置文件,并将 实现类全部实例化
- 若某个 实现类 初始化过程十分耗时 & 消耗资源,而实际又暂时用不到,则会产生浪费
- Dubbo 的 SPI 机制只有需要用到的时候,才会去配置文件中查找该 具体实现类,然后实例化,按需加载
3. 服务暴露过程
- Spring IoC 容器 refresh 完毕后,Listener 收到该广播,进行 服务的暴露
- 通过 ServiceConfig 组装 Dubbo 的
URL标签 - 通过 ProxyFactory.getInvoker() 获取
Invoker- Invoker 通过 javassist | JDK 动态代理 生成
- 通过
DubboProtocol将 Invoker 转换成Exporter, - 启动服务器 Server,监听端口
RegistryProtocol保存 URL 和 Exporter 的映射关系- 向 注册中心 注册 服务提供者 的信息
4. 服务引用流程
- 分为 饿汉式 & 懒汉式
- default = 懒汉式
服务消费者根据配置文件信息向注册中心订阅服务- 通过
DubboProtocol根据 订阅得到的 服务提供者地址 & 接口信息 创建Invoker - 通过
Invoker为 服务接口生成代理对象,通过该 代理对象 进行远程调用 服务提供者
5. 服务调用流程
- 服务消费者 通过
Invoker生成代理类,记录 该请求 & 请求 ID 等待 服务提供者的响应 - 服务提供者 接收请求后,根据 URL 找到对应的
Exporter,调用真正的实现类,进行调用,组装结果后返回给 服务消费者,携带请求ID - 服务消费者 得到该响应后,根据 请求ID 找之前存放的记录,然后将 响应结果 放入对应的
Future中,唤醒等待的线程,消费者得到响应,流程完毕
6. 负载均衡策略
1) 加权随机
- 假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。
- 现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。
- 通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,
- 计算这个随机数会落到哪个区间上就可以了
2) 加权轮询
- 比如服务器 A、B、C 权重比为 5, 3, 2,
- 那么在 10 次请求中,服务器 A 将收到其中的 5 次请求,服务器 B 会收到其中的 3 次请求,服务器 C 则收到其中的 2 次请求
3) 最小活跃数
- 每个服务提供者对应一个活跃数 active,初始情况下,所有服务提供者活跃数均为0。
- 每收到一个请求,活跃数加 1,完成请求后则将活跃数减 1。
- 在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求。
- 如果有多个 Invoker 具有相同的最小活跃数,则此时继续走 加权随机 策略
4) 一致性hash
- 通过 hash 算法,把 provider 的 invoke 和 随机节点生成 hash,并将这个 hash 投射到 [0, 2^32 - 1] 的圆环上,
- 查询的时候根据 key 进行 md5 然后进行 hash,顺时针得到第一个节点就是所求
7. 集群容错方式
1) Failover Cluster
- 失败自动切换
- dubbo 的默认容错方案
- 当调用失败时自动切换到其他可用的节点,具体的重试次数和间隔时间可用通过引用服务的时候配置,默认重试次数为 1,即只调用一次
2) Failback Cluster
- 失败自动恢复
- 在调用失败,记录日志和调用信息,然后返回空结果给consumer,并且通过定时任务每隔5秒对失败的调用进行重试
3) Failfast Cluster
- 快速失败
- 只会调用一次,失败后立刻抛出异常
4) Failsafe Cluster
- 失败安全
- 调用出现异常,记录日志不抛出,返回空结果
5) Forking Cluster
- 并行调用多个服务提供者
- 通过线程池创建多个线程,并发调用多个provider,结果保存到阻塞队列,只要有一个provider成功返回了结果,就会立刻返回结果
6) Broadcast Cluster
- 广播模式
- 逐个调用每个provider,如果其中一台报错,在循环调用结束后,抛出异常。